Turn Siloed GPUs into a Self-Service AI Factory with Virtual Clusters GPU Multitenancy and Developer Workflows

What are virtual Kubernetes clusters
Virtual Kubernetes clusters allow teams to run isolated environments while sharing underlying infrastructure resources. Combined with GPU partitioning technologies, virtual clusters support secure multi-tenant AI workloads and improve resource efficiency.
SUSE, a global leader in innovative, reliable, and secure enterprise-grade open-source solutions, today highlighted the pivotal role of SUSE Rancher Prime Virtual Clusters in industrializing artificial intelligence. By leveraging the lightweight K3k architecture, SUSE is enabling organizations to transform their standard Kubernetes environments into high-density AI workloads hosts, providing the true multi-tenancy and specialized GPU management required to move AI from pilot projects to core business operations.
While SUSE Virtual Clusters have already established themselves as a breakthrough for resource efficiency and isolation, their application as a key element of the AI Multitenancy represents a new frontier. As enterprises seek to scale AI development, they face a critical challenge: providing high-density GPU access while maintaining strict security and resource boundaries. SUSE Rancher Prime addresses this by utilizing Virtual Clusters to partition and manage GPU resources with unprecedented precision and minimal overhead.
Industrializing AI: The role of K3k in the AI multitenancy
The technical foundation of the AI Multitenancy is K3k, SUSE’s purpose-built nested Kubernetes provider. K3k is the key to achieving true multi-tenancy with a remarkably low footprint, allowing platform teams to run hundreds of independent Virtual Clusters on a single physical cluster without the performance penalties of traditional virtualization.
In the AI Multitenancy model, K3k ensures that every data science team or project operates within its own dedicated control plane. This isolation is critical for AI workloads, where experimental configurations or heavy training jobs can often destabilize standard environments. With K3k, the AI workflows remain resilient, secure, and lean, ensuring that GPU hardware is utilized to its maximum potential across the entire organization.
Strategic value for the AI age
As organizations move from AI experimentation to production-grade deployments, the ability to manage workloads at scale becomes the primary differentiator. SUSE Rancher Prime leverages its industry-leading position in multi-cluster management to provide a consistent experience across edge, core, and cloud.
The integration of GPU-based workloads into the virtual cluster framework allows organizations to maximize their hardware investment. Instead of dedicated, underutilized physical nodes, companies can now dynamically allocate GPU slices to virtual clusters as needed, improving overall efficiency and reducing total cost of ownership.
Precision control: The platform administrator flow
For platform administrators, the AI Multitenancy is managed through a streamlined, policy-driven workflow. By relying on Virtual Cluster Policies (VCP), administrators can move beyond manual setup to a dynamic, automated infrastructure model:
- Defining AI Guardrails: Admins use Virtual Cluster Policies to establish the right level of isolation for specific AI projects. This includes pre-configuring security contexts, networking, and resource limits, ensuring every AI workflow is compliant from the moment it is spun up.
- Dynamic GPU and Quota Allocation: Within the policy, administrators can allocate GPU resources and set granular quotas. This allows the platform to balance the needs of GPU-intensive training against traditional workloads within the same environment, preventing any single instance from impacting the performance of the whole cluster.
- Automatic Resource Reflection: A standout capability of this architecture is the seamless link between policy and infrastructure. When an administrator adjusts a Virtual Cluster Policy, such as increasing a team’s GPU allocation, the changes are automatically reflected in the Virtual Cluster’s allocatable resources. This dynamic update happens without manual intervention or cluster restarts, allowing the AI workflows to scale in real-time.
- Integrated Platform Experience: This approach offers a coherent, end-to-end experience within SUSE Rancher Prime. Administrators can manage the entire lifecycle of their AI infrastructure using the same familiar tools, RBAC, and observability they use for their traditional Kubernetes workloads.
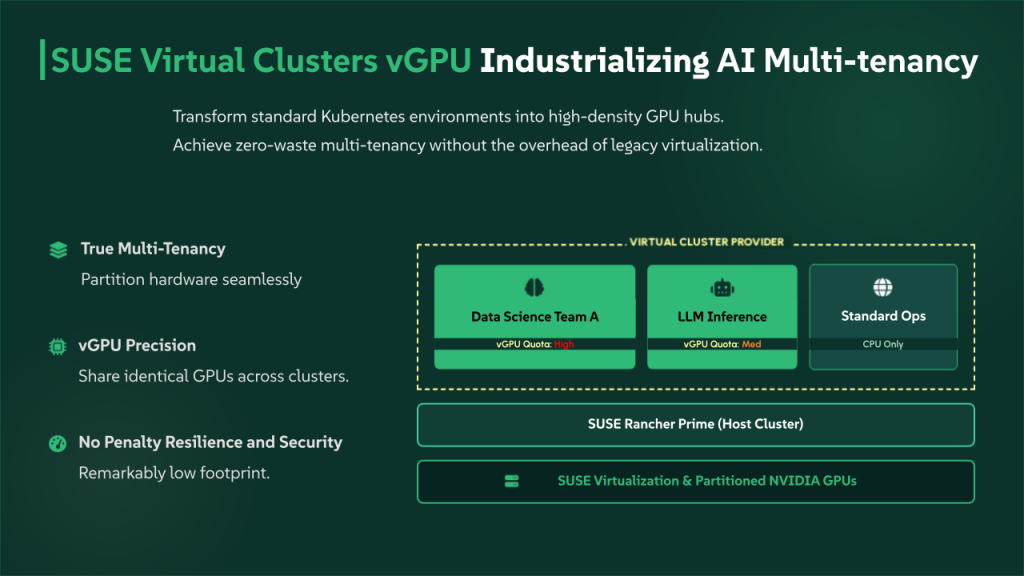
Virtual Cluster vGPU Multi-Tenancy
Seamless integration and isolation
Once the GPU-enabled Virtual Cluster is provisioned, the developer can target it as they would any standard Kubernetes cluster. The environment is completely isolated, allowing for the installation of specific CUDA drivers, AI frameworks, and proprietary libraries required for the application.
This isolation is critical for AI development, where versions often conflict. By confining these changes to a virtual cluster, SUSE ensures that the developer can test destructive or experimental configurations without impacting other teams or the primary management plane.
Operator confidence through guardrails
All GPU-enabled Virtual Clusters are subject to strict resource quotas. These guardrails prevent a single developer or project from exhausting the cluster’s expensive hardware resources, ensuring fair access across the enterprise.
“The pace of AI development is relentless, and our goal is to ensure that infrastructure never becomes the bottleneck,” said Peter Smails, General Manager of the Enterprise Container Management business unit at SUSE. “By bringing GPU capabilities to Virtual Clusters, we are providing developers with the ‘sandbox’ they need while giving operators the control they require.”
Empowering AI-driven workflows
The modern developer workflow requires more than just compute; it requires the flexibility to iterate rapidly in environments that mirror production scale. SUSE Rancher Prime now enables developers to treat GPU resources as first-class citizens within virtualized Kubernetes environments.
When a developer initiates the creation of a new Virtual Cluster, the platform automatically detects available GPU devices assigned to the host environment. A new GPU-enablement toggle allows the developer to claim these resources for their specific instance. This self-service approach removes the bottleneck of waiting for administrative intervention, significantly reducing the time from concept to code.
Scaling the future of intelligence
“The release of SUSE Virtual Clusters was just the beginning; today, we are showing how they serve as the essential engine for the modern AI Multitenancy,” said Jean-Philippe, Product Manager . “By combining the low footprint of K3k with advanced GPU multi-tenancy and automated policy management, we are giving enterprises a unique path to industrialize their AI initiatives. We’ve removed the friction of resource allocation so that platform teams can focus on what matters: delivering the compute power that drives innovation.”
SUSE Rancher Prime continues to set the standard for enterprise-grade Kubernetes, providing the security and flexibility required to bridge the gap between traditional operations and the next generation of AI-driven applications.
Come see us at KubeCon EU in Amsterdam.
Visit the SUSE booth, join our sessions, and experience firsthand what an AI-native cloud native platform can do for your organization.
For the latest updates, visit suse.com/kubecon and follow us on social media throughout the week.
Related Articles
May 16th, 2025
Is Cloud Native Telco the Future of Communication?
May 29th, 2026