Local AI and Confluence
Introduction
This post is part of a series on locally using AI models. Previous posts are
Generating images with LocalAI using a GPU
Introduction to AI training with openSUSE
Adding own Documents to your Local AI Using RAG
In the last post I explained how to use RAG to add your own documents to the knowledge of local AI models. This is helpful for simple use cases, but often you have data in some kind of database and and want to make this data available to an LLM, and this also is possible with not too much effort..
One of the documentation and knowledge databases widely used in many companies is Confluence. I’ll show in the next sections on how to embed data from a Confluence database while keeping all data inside the local network. This is a great use case for a LocalAI deployment given that we do not want any of the private data to leave the company premises.
Requirements
The following instructions assume a running LocalAI container deployment. To deploy and use LocalAI, please read Running AI locally for a cpu only setup or Generating images with LocalAI using a GPU if you want to use a Nvidia GPU. Beside this, you only require additional disk space for the RAG data and some more docker containers.
RAG and Data Connectors
Using a structured database as RAG source is not much different than uploading pdf or text files to be embedded. All you need to do is to retrieve data from the database using a so called data connector. As OpenWebUI, the application used in my previous RAG related post, has no data connector functionality yet (it is planned though), I’m using AnythingLLM this time instead.
AnythingLLM
AnythingLLM is like OpenWebUI an AI application with a web frontend. It also can use LocalAI as backend and is comparable in features to OpenWebUI, but also has some data connectors built in, including a Confluence connector which I’ll be using in this post. Please note that in its current implementation, the data connectors only fetches data from the database once and to keep data in sync, repeated data connector usage is required. AnythingLLM contains a experimental beta feature to keep the data source in sync, but it is not currently recommended for production use yet.
Adding a Container Network
Deploying AnythingLLM as container requires the building of the container first and so it can’t be just added as snippet to the existing LocalAI docker-compose.yaml file, like with OpenWebUI. Instead, you’ll have to configure a docker network in the existing LocalAI docker-compose.yaml, and then build and start the AnythingLLM container separate, connecting it to the LocalAI containers through the defined container network.
To define and use a network for your existing LocalAI docker compose configuration, add the sections in red to your existing LocalAI docker-compose.yaml.
- For CPU only:
networks: localai: name: localai driver: bridge driver_opts: com.docker.network.bridge.host_binding_ipv4: "127.0.0.1" services: api: image: localai/localai:latest-aio-cpu healthcheck: test: ["CMD", "curl", "-f", "http://localhost:8080/readyz"] interval: 1m timeout: 20m retries: 5 ports: - 0.0.0.0:8080:8080 environment: - DEBUG=true - THREADS=6 volumes: - ./models:/build/models:cached networks: - localai
- With GPU:
networks: localai: name: localai driver: bridge driver_opts: com.docker.network.bridge.host_binding_ipv4: "127.0.0.1" services: api: image: localai/localai:latest-aio-gpu-nvidia-cuda-12 deploy: resources: reservations: devices: - driver: nvidia count: 1 capabilities: [gpu] healthcheck: test: ["CMD", "curl", "-f", "http://localhost:8080/readyz"] interval: 1m timeout: 10m retries: 20 ports: - 0.0.0.0:8080:8080 environment: - DEBUG=true volumes: - ./models:/models:cached networks: - localai
Now restart with
> docker compose restart
And verify that a network named localai exists with
> docker network list
NETWORK ID NAME DRIVER SCOPE
...
dca213c23ab4 localai bridge local
...
Now it is possible to run AnythingLLM from a separate docker compose setup and have it connect to the LocalAI containers through this network. Please also add this section to all other services that you might have configured within your LocalAI docker-compose.yaml:
networks: - localai
Configuration
- Clone AnythingLLM in a convenient location and go to the docker directory that is inside the repo:
> git clone https://github.com/Mintplex-Labs/anything-llm.git > cd anything-llm/docker
- Create a .env file with the following content to configure AnythingLLM for use with LocalAI
LLM_PROVIDER='localai' EMBEDDING_MODEL_PREF='text-embedding-ada-002' LOCAL_AI_BASE_PATH='http://api:8080/v1' LOCAL_AI_MODEL_PREF='gpt-4' LOCAL_AI_MODEL_TOKEN_LIMIT='4096' LOCAL_AI_API_KEY='sk-123abc' EMBEDDING_ENGINE='localai' EMBEDDING_BASE_PATH='http://api:8080/v1' EMBEDDING_MODEL_MAX_CHUNK_LENGTH='1000' VECTOR_DB='lancedb' WHISPER_PROVIDER='local' DISABLE_TELEMETRY='true' TTS_PROVIDER='generic-openai' TTS_OPEN_AI_COMPATIBLE_KEY='sk-example' TTS_OPEN_AI_COMPATIBLE_VOICE_MODEL='tts-1' TTS_OPEN_AI_COMPATIBLE_ENDPOINT='http://api:8080/v1' STORAGE_DIR='/app/server/storage' SERVER_PORT='3001
All of these settings can also be changed in the AnythingLLM settings later.
- Add the sections in red to docker/docker-compose.yaml to add the localai network
name: anythingllm networks: anything-llm: driver: bridge localai: external: true services: anything-llm: container_name: anythingllm build: context: ../. dockerfile: ./docker/Dockerfile args: ARG_UID: ${UID:-1000} ARG_GID: ${GID:-1000} cap_add: - SYS_ADMIN volumes: - "./.env:/app/server/.env" - "../server/storage:/app/server/storage" - "../collector/hotdir/:/app/collector/hotdir" - "../collector/outputs/:/app/collector/outputs" user: "${UID:-1000}:${GID:-1000}" ports: - "0.0.0.0:3001:3001" env_file: - .env networks: - anything-llm - localai extra_hosts: - "host.docker.internal:host-gateway"
Building and Running
Since AnythingLLM will be built using containers, no special changes of the host system are required.
Run
> docker compose up
and watch the container building and starting. Once it is running, try to access https://localhost:3001 to see if it is accessible. You should see a interface looking something like this:

Multi User
Since data will be downloaded from the database and embedded with the LLM, it highly is recommended to enable password protection or multi user mode for AnythingLLM, to prevent the data from being available to other users in the local network. To do this, go to Settings->Security and enable Multi User Mode if you have more than one user for the system, or Password Protection if you are the sole AnythingLLM user

Once this is done, you should be greeted by a login screen

Login with your admin account. You’ll get a popup with recovery codes. Make sure to store those, as they are the only way to reset the admin password.
Confluence
Now that everything is prepared, the data connectors can be used. To do that, create a new workspace and call it confluence.

Click on upload a document, or the upload icon beside the workspace name in the tab on the left to get to the documents dialog:

Click on Data Connectors on the top, select Confluence and fill out the required values:
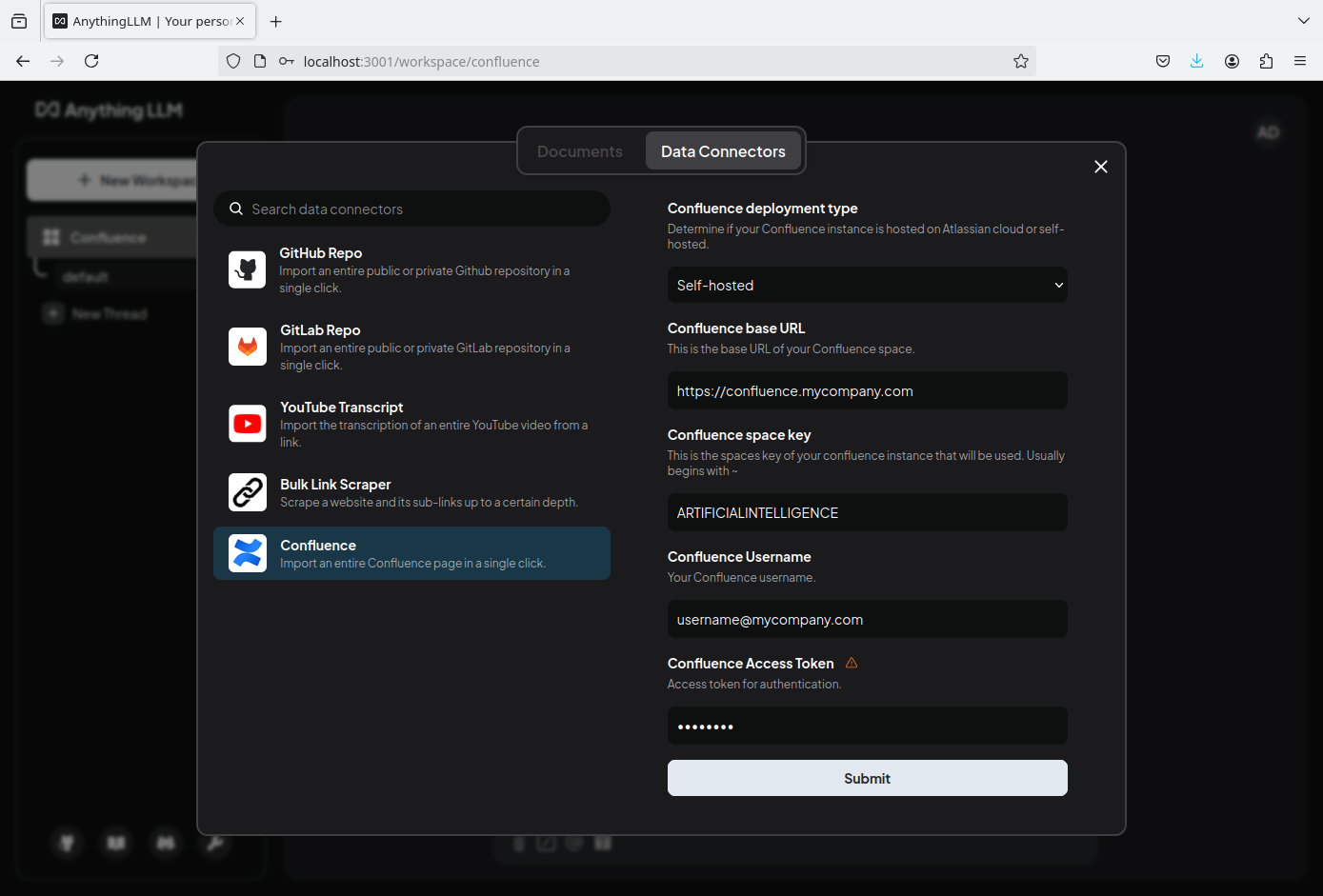
Please note that it is only possible to enter username/access token, which will be used for basic authentication with the Confluence server to access the Confluence API. If your local Confluence installation does not allow basic auth and requires a Confluence PAT (Personal Access Token), you will need some modification to AnythingLLM to use PAT based authentication:
https://github.com/greygoo/anything-llm/commit/7811d57bb4bf695ef6c9120e57ca35bcba1258ea
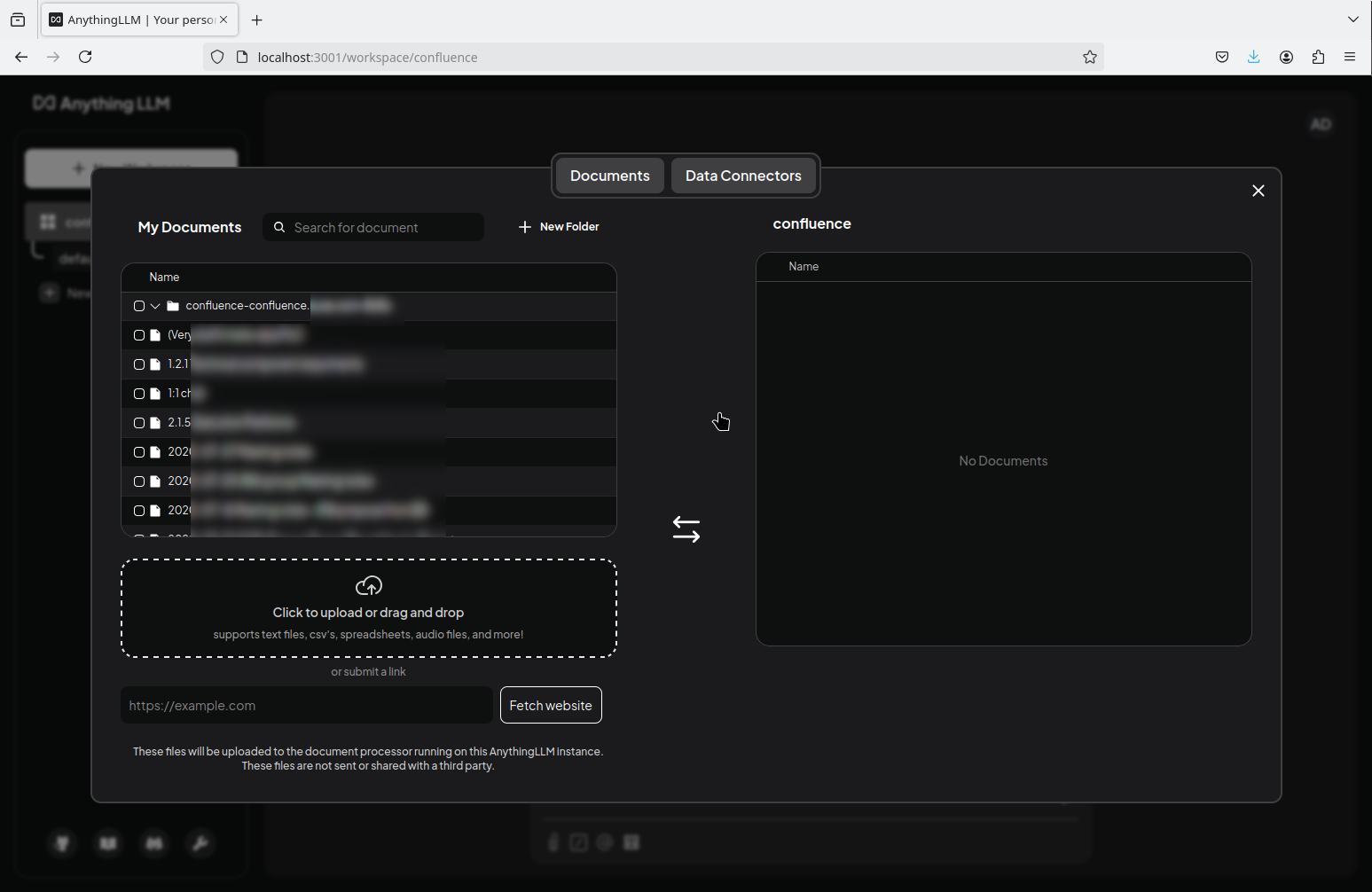
Once you click submit, AnythingLLM will download all documents from the Confluence space defined by the Space Key and add them to the documents overview:
Select them by clicking the top checkbox in the left tab and click Move to Workspace:
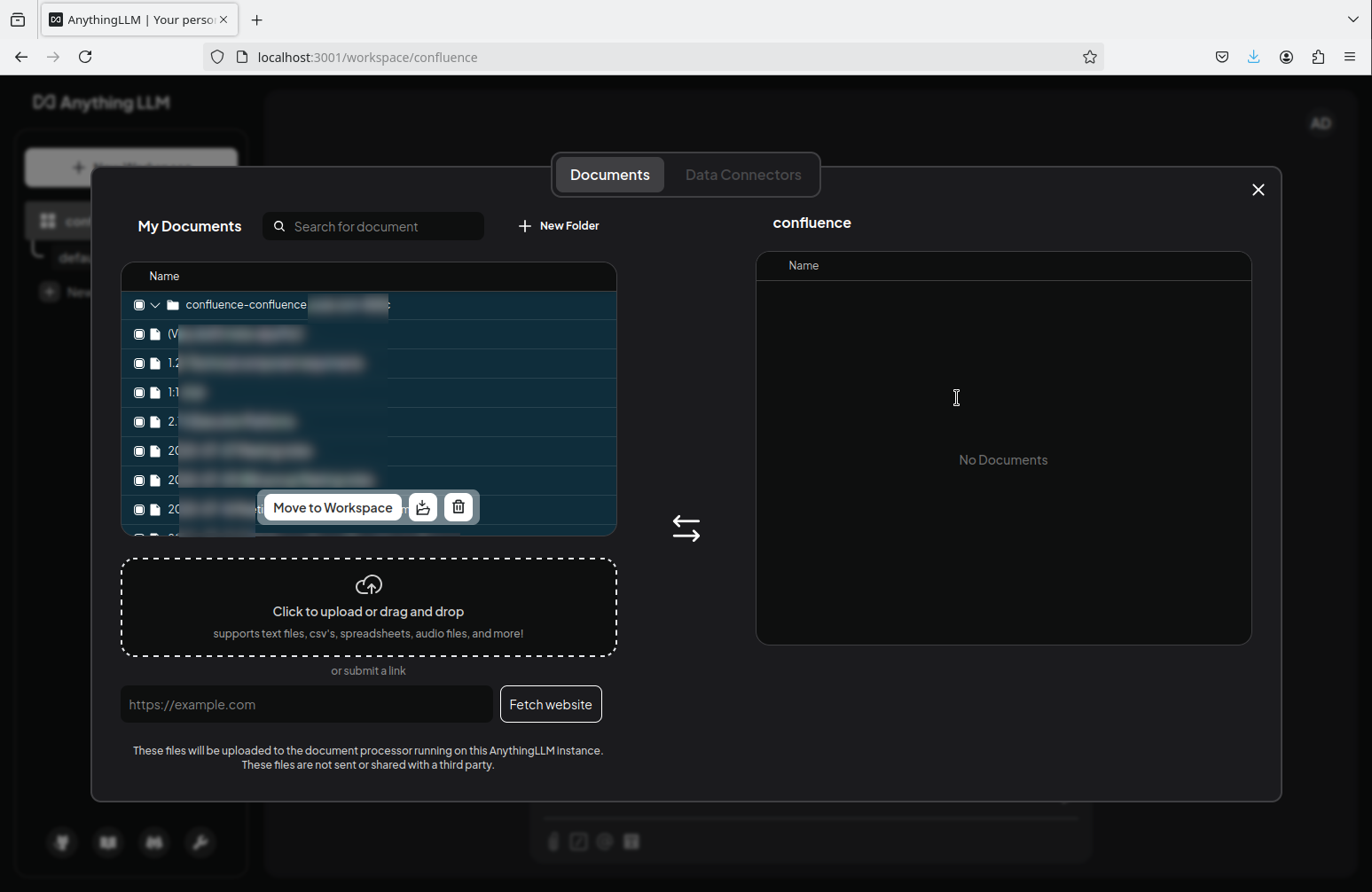
This adds all files to the right tab, and now you can click Save and Embed:

AnythingLLM now sends all files to LocalAI for vectorisation and embeds them with the model.
To test the embedding, I created a test page inside the Confluence space that contains information not previously known to the model:
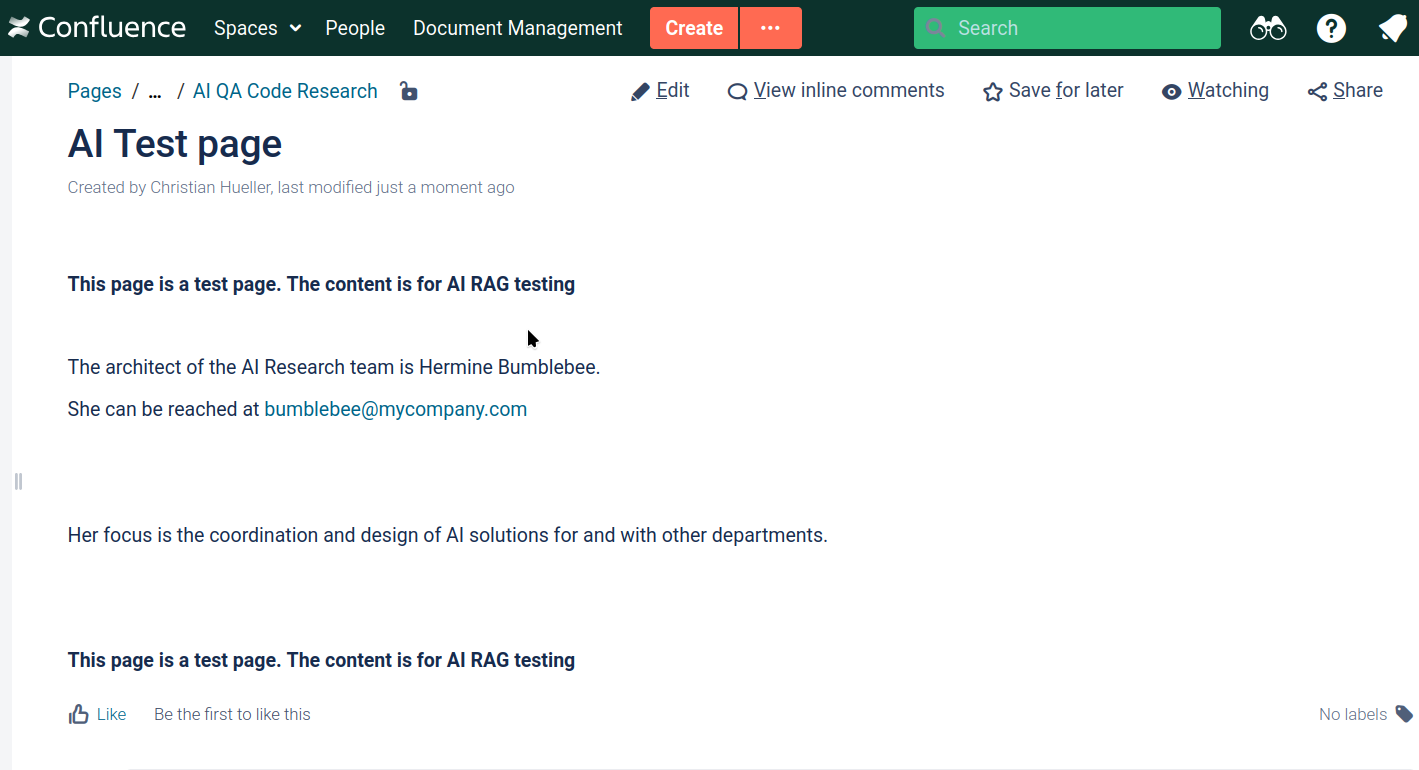
When prompted for this information after embedding the Confluence Space, it answers correctly:

Syncing (Experimental)
As mentioned earlier, the Data Connector only fetches the data from the Confluence data base once, so if you want to update your embedded files, you have to repeat the process and replace the previously embedded data with new one. AnytingLLM provides an experimental preview feature to enable syncing of data sources, however it comes with a huge warning about potential data loss or corruption. If you like to try it out, please consult the AnythingLLM documenttion for it, if you like to experiment.
Summary
Having a LocalAI instance inside your network makes it easy to use additional data sources through data connectors and enables them to provide answers with knowledge that stays confined within the local network. This enables a much more powerful way to search for information especially in larger systems than the simple full text search that is available normally. And as with Confluence, other data sources like github can be used to e.g. embed code bases with a model and use that for code related tasks like test generation.
Related Articles
Feb 20th, 2025