Cloud Cost Management with ML-based Resource Predictions (Part II)
Cloud and Kubernetes cost optimization has huge promise and pointing exciting new technologies and methodologies at the problem is accelerating the fulfilment of that promise. We’ve invited Prophetstor, a SUSE One partner, to share valuable insights and their experience with tackling today’s cloud cost management challenges to speed your time to maximum value from your cloud and Kubernetes deployments.
In part two of this two part series (see part one), they’ll cover continuous rightsizing along with performance and cost optimization. ~Bret
SUSE GUEST BLOG ARTICLE AUTHORED BY:
Ming Sheu, EVP Products, ProphetStor
Reducing Cost by Continuous Rightsizing
As outlined in the Guidance Framework introduced in part one of this post, once users gain visibility of spending metrics, they must see opportunities to reduce monthly bills. Federator.ai provides the visibility of cloud spending at different resource levels (clusters, cluster nodes, namespaces, applications, containers), and it makes finding ways to reduce the cost an easier task. For example, it is well documented that most containers deployed in Kubernetes clusters use far less allocated CPU and memory resources. This indicates a huge opportunity to reduce the overall cloud cost by allocating the appropriate resources for applications. However, finding the right size of resources for applications is not straightforward. With Federtor.ai’s predictive analytics, users receive the right recommendations on resource allocation without suffering potential performance risks.
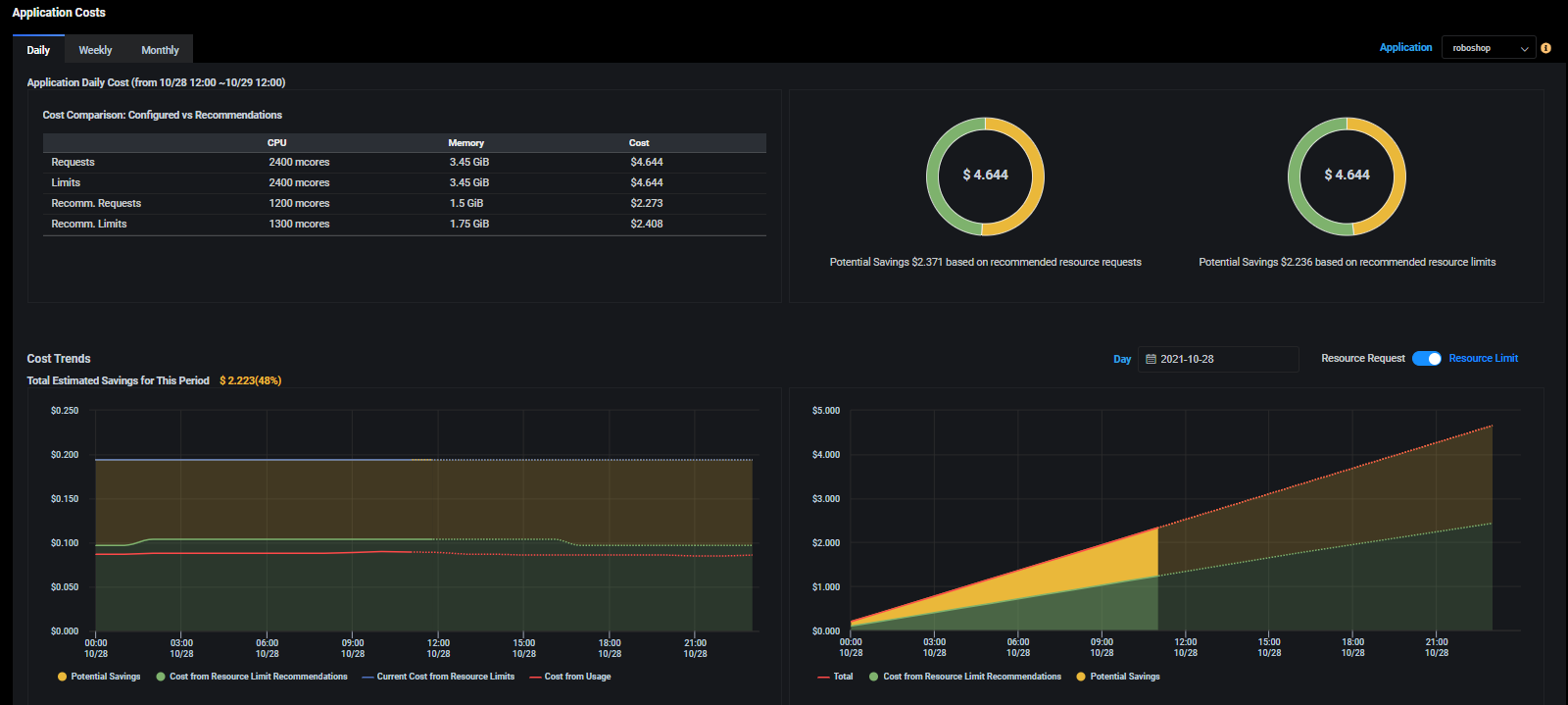
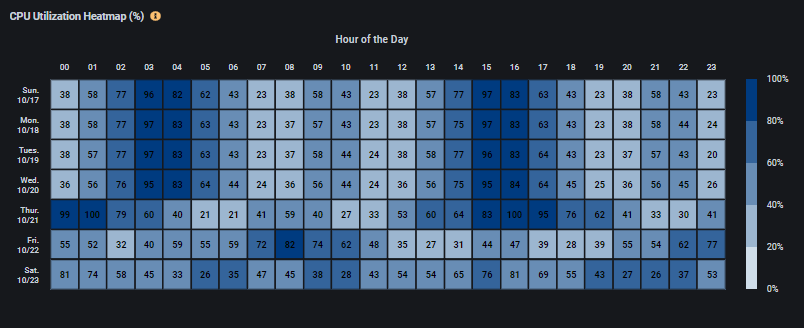
An essential suggestion by the Guidance Framework when looking to reduce the cost of deployment is to understand the utilization patterns of applications and services. Users should schedule cloud services and applications based on the utilization pattern from the historical data collected. Federator.ai not only provides a resource utilization heatmap based on historical usage metrics, but it also provides a utilization heatmap that further sheds light on how resources will be consumed in the future. The utilization patterns, either daily, weekly, or monthly, give users a clear view of both when and how much resources were used and will be used. This information helps users to decide what compute instances could be reduced or shut down during off-hours without performance impact.
The Guidance Framework also recommends right-sizing allocation-based services as an effective way of reducing the cost. It is well known that many applications end up using resources at a much smaller percentage of allocation. When this happens, one must right-size the resource to reduce the cost. As suggested by the Guidance Framework, one must monitor resource utilization over a defined period to implement right-sizing. Frederator.ai allows users to set up a utilization goal and gain visibility of potential savings from continuously right-sizing the resource allocation. Good practice in controlling cost is setting up specific resource utilization goals to provide certain headroom for the possible unexpected workload increase and minimize the potential waste. With workload prediction, Federator.ai can facilitate continuous right-sizing of resources that meet the utilization goal.
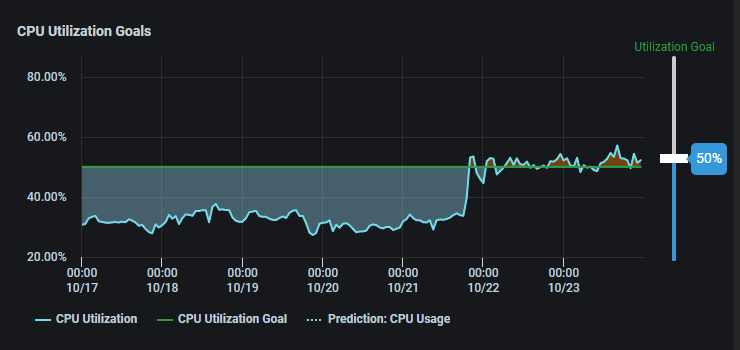
As stated in the Guidance Framework, right-sizing is one of the most effective cost optimization best practices. In addition, Federator.ai’s automated continuous resource optimization makes matching the users’ utilization goal an easy task.
Optimizing Performance and Cost
Optimizing cloud spending goes beyond the tactical cost reduction techniques mentioned in the Reduce component of the Guidance Framework. Most public cloud service providers offer compute instances at a much lower price than the standard pay-as-you-go model. Some of those with discounted offers are from a commitment of the compute instances, such as reserved instances. If one can analyze the utilization of compute instances over time, it is possible to significantly reduce the cloud build with the use of reserved instances. The other type of cost savings can be achieved by a different type of instance: spot instances. These compute instances are preemptible, meaning the compute instances might be returned to the service providers when the availability of compute instances is low. Spot instances offer a lot lower price compared to the standard pay-as-you-go model. However, the application that runs on those spot instances needs to tolerate the possible interruption when the service providers reclaim the spot instances.
The Guidance Framework recommends that organizations should look into leveraging the preemptible instances to gain significant cost benefits if application workloads can adapt to their limitations and the risk of unavailability can be mitigated. Federator.ai analyzes the cluster usage, forecasts future resource needs, and recommends the best combination of reserved, spot, and on-demand instances that can handle the cluster workload with optimized cloud cost. Users can further apply additional search criteria such as the country/region of the instances and/or specific public cloud service providers.
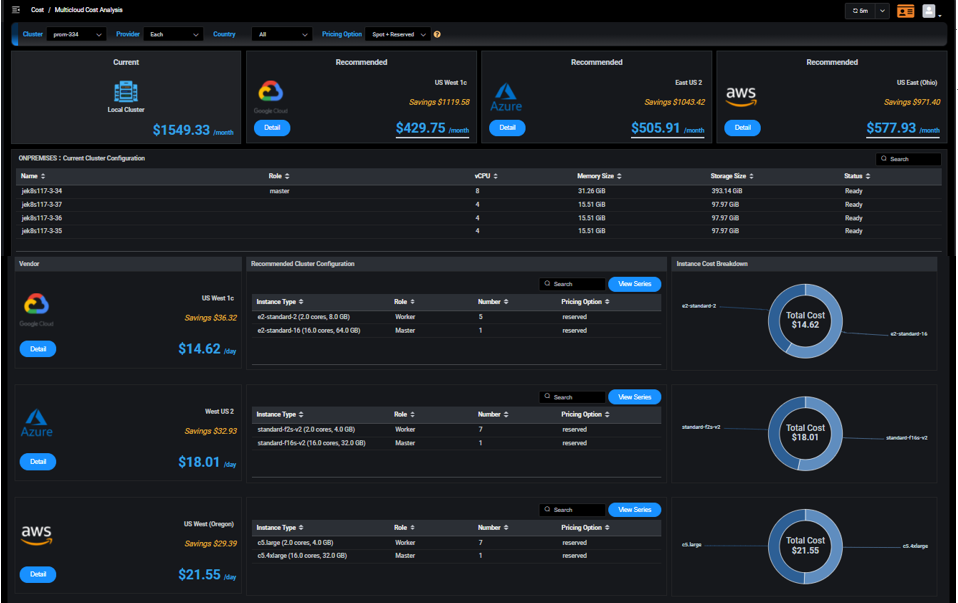
Another valuable mechanism of optimizing the cloud cost without sacrificing performance recommended by the Guidance Framework is horizontal autoscaling. The modern cloud-native applications are implemented in microservice architecture that scaling the application to handle large workloads by configuring with enough microservice replicas (or pods). The cost of running an application, of course, depends on the total number of these replicas (pods) instantiated for this application. Since application workload is dynamic, it will be a waste of resources with a large number of replicas when the workload is low. Horizontal Pod Autoscaling (HPA) in Kubernetes is a great way to adjust the number of replicas for different workloads dynamically. When HPA is done right, one can achieve significant savings when running applications. Federator.ai’s intelligent HPA takes this concept further and utilizes the workload predictions to accurately increase/decrease the number of replicas just in time for the workload changes. This transforms HPA from a reactive basis to a proactive basis.

Federator.ai and the SUSE Rancher Apps and Marketplace
Managing cloud costs is an essential and challenging task for organizations using cloud services to drive their business with greater efficiency. In partnership with SUSE, Prophetstor’s Federator.ai provides an effective cloud cost management solution for customers running applications on SUSE Rancher-managed clusters. Federator.ai’s ML-based cost management implements some of the most valuable recommendations from the Guidance Framework and brings tremendous values to users adopting this framework. ProphetStor Federator.ai is currently available on SUSE Rancher Apps and Marketplace and is fully supported on both a SUSE Rancher instance as well as a Rancher open source project deployment.
For more information on Federator.ai, please visit prophetstor.com.
 Ming Sheu is EVP of Product at ProphetStor with more than 25 years of experiences in networking, WiFi systems, and native cloud application. Prior to joining ProphetStor, he spent 13 years with Ruckus/CommScope in development of large scale WiFi Controller and Cloud-based network management service.
Ming Sheu is EVP of Product at ProphetStor with more than 25 years of experiences in networking, WiFi systems, and native cloud application. Prior to joining ProphetStor, he spent 13 years with Ruckus/CommScope in development of large scale WiFi Controller and Cloud-based network management service.









 As a Product Marketing Manager at phoenixNAP,
As a Product Marketing Manager at phoenixNAP,