An Introduction to SUSE Manager for Retail
SUSE Manager for Retail is an open source infrastructure management solution that is optimized and tailored for the retail industry.
You can use SUSE Manager for Retail to deploy and manage point-of-service terminals, kiosks, self-service systems, and reverse-vending systems, as well as other Linux-based assets within your infrastructure. SUSE Manager for Retail provides a single user interface for handling tasks such as :
- Creating Linux client images that are optimized for retail applications, including support for secure payments protocols
- Deploying system images in a wide range of retail scenarios, from remote provisioning to broadband connections, to fully offline installation with physical media
- Keeping legacy retail hardware in operation even when the system resources are too limited to support other operating systems
- Automatically updating or patching all retail terminals from one central location
- Monitoring the health of your entire retail environment
- Detecting non-compliant systems or unauthorized changes to systems within the retail environment
SUSE Manager for Retail can reduce costs, streamline operations, increase flexibility, enhance reliability, and improve uptime for the complete lifecycle of your retail infrastructure.
System Architecture
At the core of the SUSE Manager for Retail environment is Linux – a secure and stable open source operating system used by thousands of large organizations for mission-critical tasks. Linux is designed to keep kernel and user processes strongly separated, which leads to stability and a natural resistance to intrusion and malware.
Linux is also very easy to mold and modify for specialized use. SUSE Linux Enterprise Point of Service (SLEPOS) is a Linux-based, point-of-service client designed to serve as a retail client within the SUSE Manager for Retail environment. SLEPOS is engineered to achieve tight security with minimal footprint and maximum security and performance. SLEPOS uses the versatile SUSE Linux Enterprise operating system as a base platform. The default version of SLEPOS integrates several retail-specific services and standards, such as Payment Card Industry (PCI) Data Security, with world-class open source security tools for VPN, secure shell, firewall, and more. Because SLEPOS is Linux, you can add additional applications as needed, build custom applications, or create a custom system image to automate installation for a large number of devices. You can install SLEPOS on a dedicated POS device or on any standard PC. Minimal SLEPOS images require as little as 512 MB of RAM, which means SLEPOS can extend the life of older point-of-service (POS) systems.
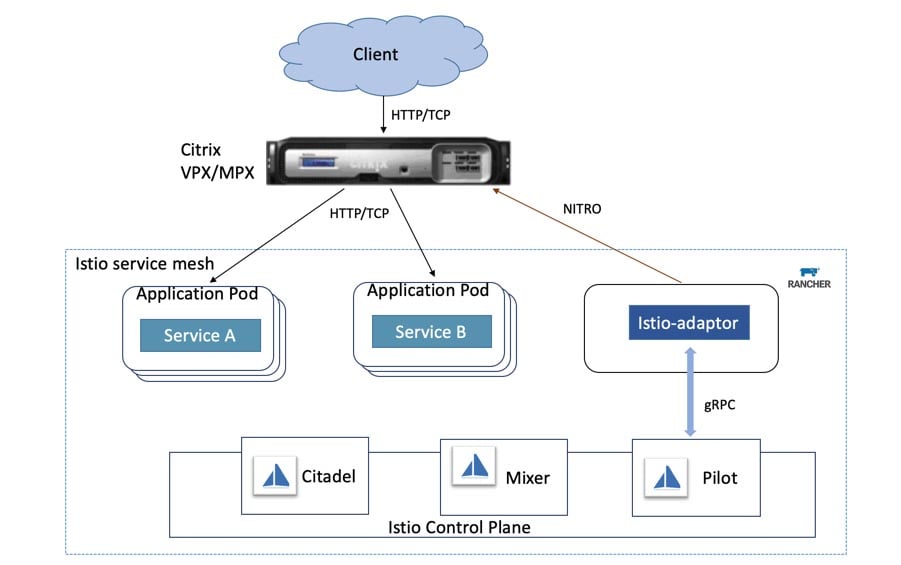
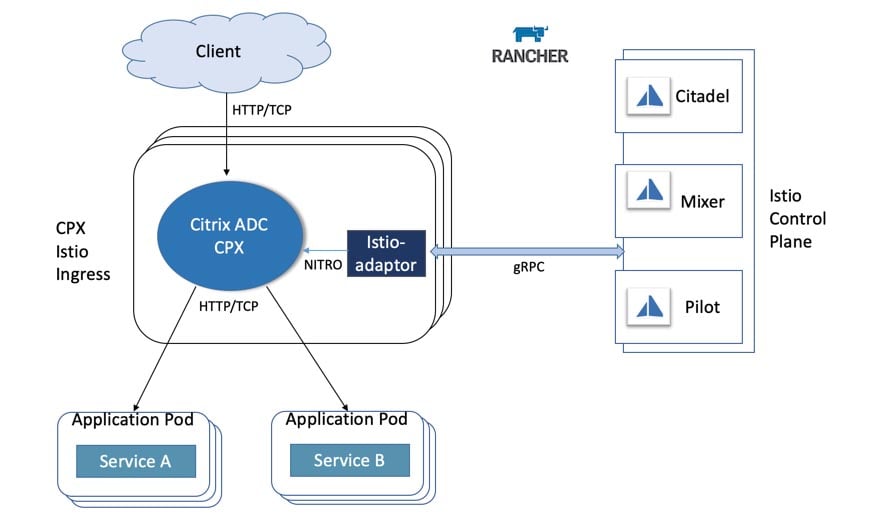
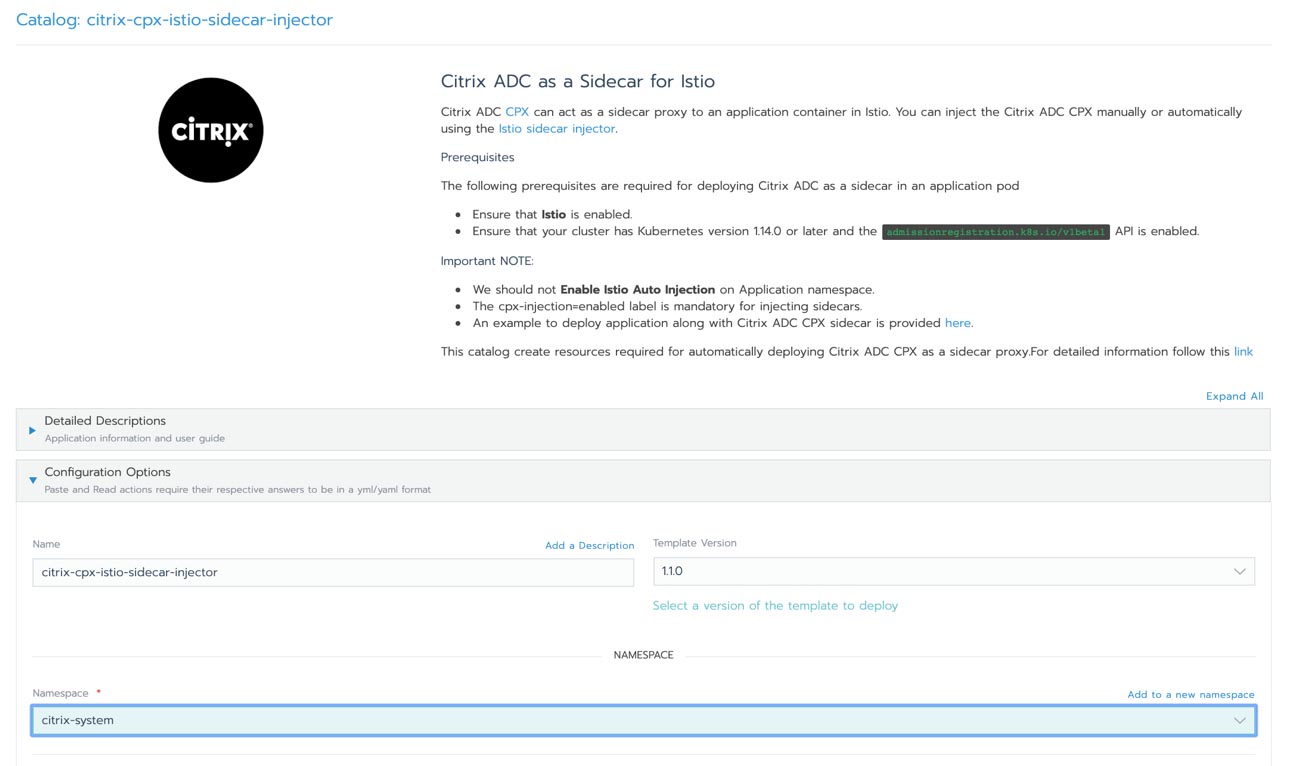
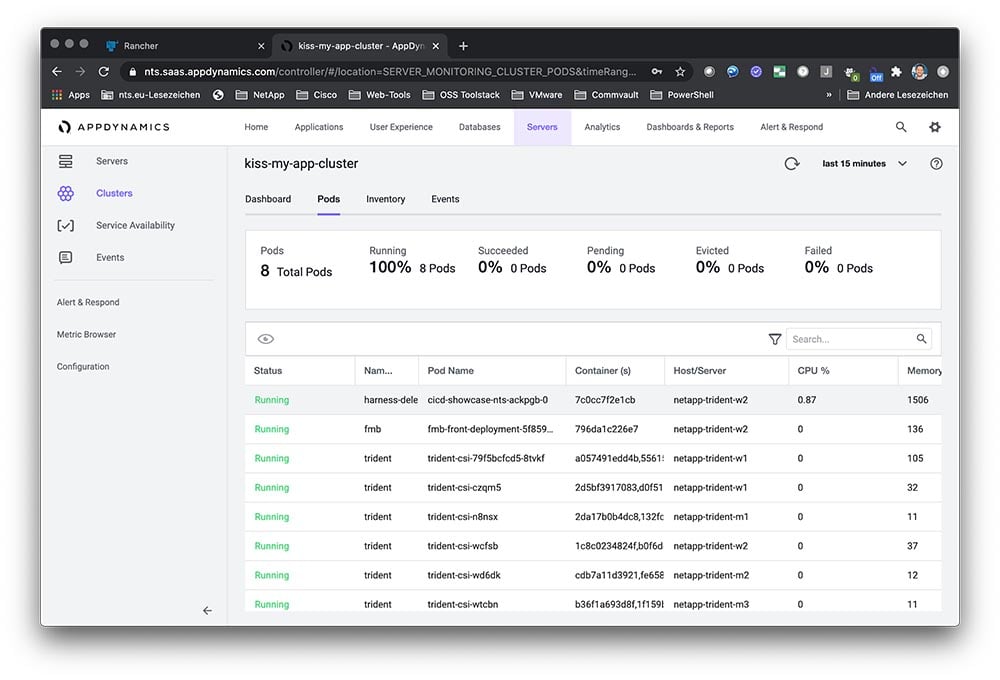
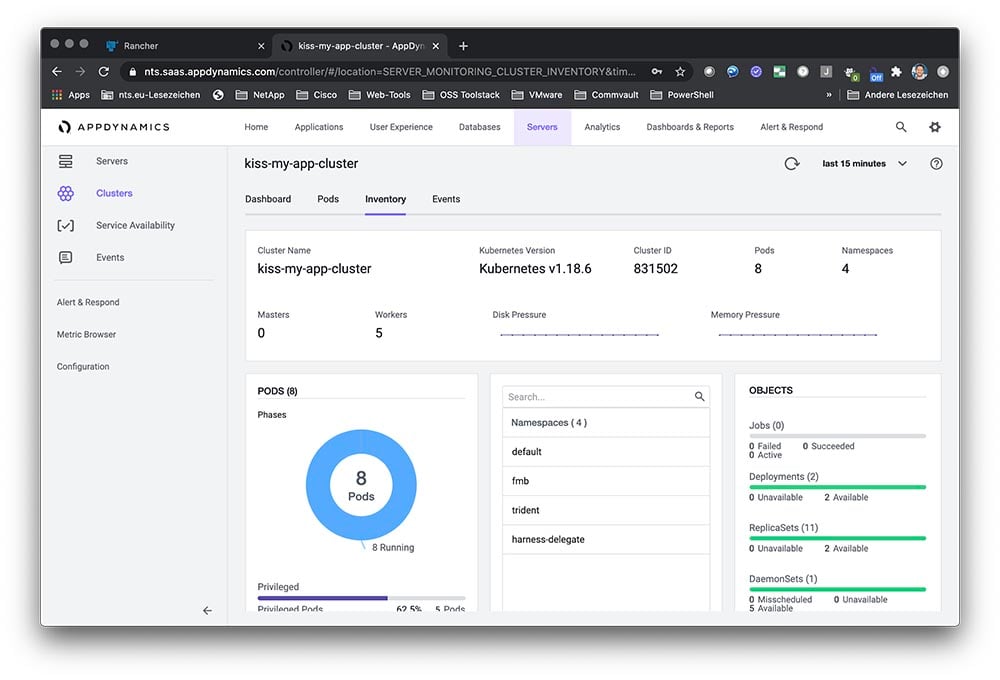
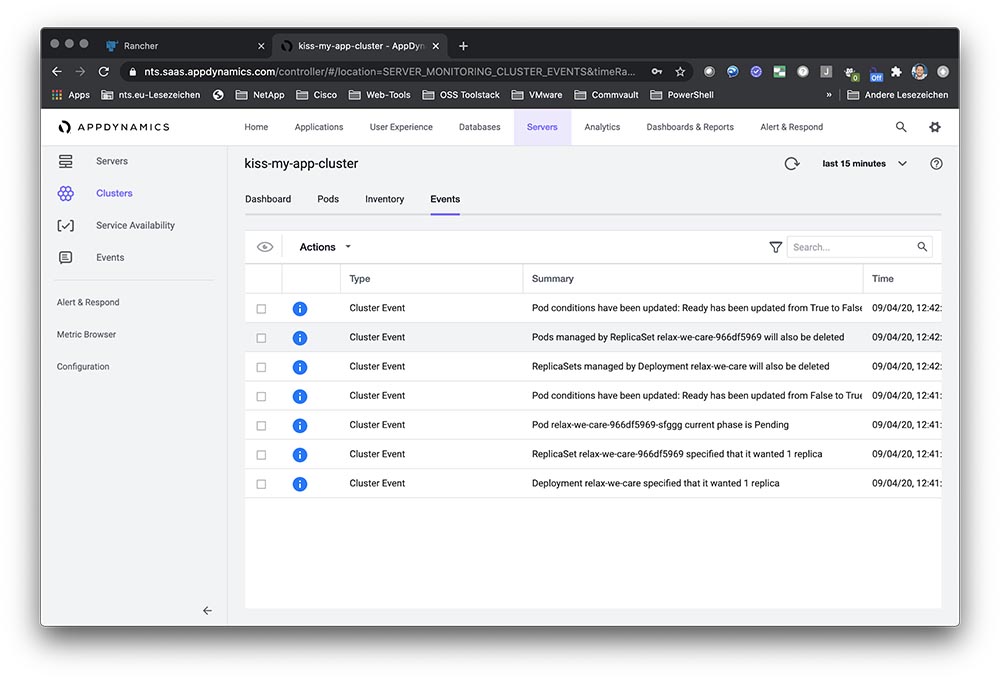
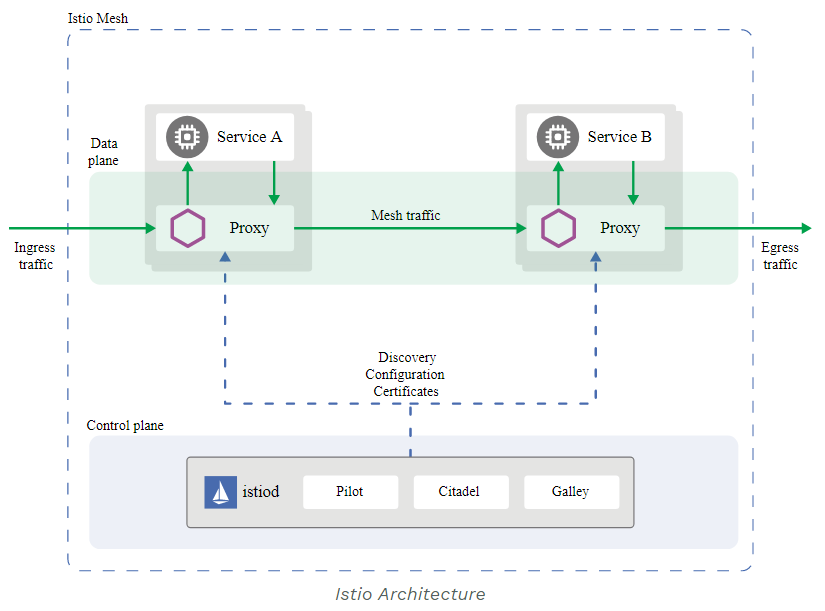
The architecture of a typical SUSE Manager for Retail network is shown in the figure. The retail devices are organized into branches. Each branch represents a local office or retail outlet at a single location.
The environment consists of:
- SLEPOS retail client systems
- A SUSE Manager for Retail branch server (operating at each branch location, datacentre, or cloud)
- A SUSE Manager server to deploy and oversee the complete environment
Note: It is not mandatory to have a branch server is every branch, the SUSE Manager for retail architecture allows branch server to be deployed wherever optimally suited, based typically on a cost/performance requirements criteria.
Also shown in the figure are the Customer Center, an online service that helps you manage subscriptions and offers an interface with SUSE support resources, and the Subscription Management tool, a proxy system for the SUSE Customer Center with repository and registration targets.
The complete infrastructure shown in the figure could be as small as a single local shop, or it could consist of thousands of POS systems in multiple remote locations.
The SUSE Manager server lets an administrator operating from the main office view the status and proactively monitor any POS system on the network. The administrator can provision new systems, control software updates, and monitor all systems for compliance with security standards. All the systems shown in the figure are open source, which means you’ll never suffer from the vendor lock-in associated with proprietary software systems.

SUSE Manager Server
The SUSE Manager Server, which usually runs in the main office behind a firewall, is at the center of the SUSE retail management infrastructure. The SUSE Manager server controls the creation of client images, software distribution to the terminals, update procedures, and compliance checks.
The SUSE Manager server is a component of the main SUSE Manager product used for managing Linux systems in enterprise environments. For the retail edition, SUSE adds functions and extensions needed for managing retail branch servers and clients.
The upstream project for SUSE Manager, called Uyuni, is publicly developed on GitHub, with frequent releases and solid, automated testing. Although Uyuni is not commercially supported by SUSE and does not receive the same rigid QA and product lifecycle guarantees, it is a full version of the software. Unlike other vendors, whose commercial products heavily rely on extra features not available in the basic, open source version, SUSE keeps the full feature set available in the community edition.
Branch Server
The branch server of a SUSE Manager for Retail installation controlling all the retail terminals within a defined branch environment. The SUSE Manager for Retail branch server is a technical equivalent of the standard SUSE Manager Proxy Server, with enhanced functionality for the retail environment. The branch server acts as a multipurpose server system and you can use the branch server to manage PXE remote boot for POS clients, as well as to provide DHCP, DNS, FTP, and other services for the branch. The branch server can also act as an image cache, Salt broker, and proxy server for remote package updates.
Maintaining a branch server at the local level many be beneficial for larger stores lowers the overall bandwidth needs of the retail IT network (which may very well be scattered across hundreds or thousands of kilometers), lightens the processing load on the SUSE Manager server, and generally speeds up operations.
The branch server:
- manages the synchronized distribution of terminal system images and software updates to all the retail terminals in the same store environment
- provides the network boot and system management infrastructure for retail terminals
- serves as a generic system platform for in-store applications, such as database systems and as a back end for POS applications
Powerful Image Building for Retail Terminals
Daily operations in modern retail stores might appear to be a pretty small set of standard procedures. IT managers of those stores, however, know all too well that reality is often very different. Corporate acquisitions or changing hardware suppliers may result in an assortment of different terminals that require different hardware drivers or boot procedures. Suburban stores with bad internet connectivity may need different software update procedures from those in large urban centers. International companies might need different software localizations and different payment systems for different locations.
System administrators of retail chains often have to install many different software images in the terminals on their network. SUSE Manager for Retail makes it easy to customize and adapt system images.
The SUSE Manager server sets up an instance of the open source KIWI image builder. You can uses Kiwi to create software images for POS clients and other Linux systems. KIWI lets you create as many image templates as you need to handle standard configurations, then customize the images as necessary to accommodate local conditions or specific design requirements. SUSE Manager for Retail augments KIWI with an easy-to-use interface for centralized management and administration of POS images. SUSE Manager for Retail also ships with a collection of pre-configured image templates.

User Interfaces
The Web-based user interface of SUSE Manager for Retail enables users to move easily among all tasks while keeping a clear view of network resources. A sidebar menu gives constant access to all the high-level functions and components of your network, and it is possible to see the network itself with clusters of stores grouped and connected as they actually are.

You can also access a context-sensitive legend for the symbols used by SUSE Manager, breadcrumb navigation, buttons to quickly go back to the top of each window, and a dedicated search box for the menu sidebar.
Once you have completed the initial configuration, the System Set Manager (SSM) provides an efficient way to administer many systems simultaneously. After you have selected the systems on which you want to work, the main SSM window gives you quick access, through one set of tabs, to all the controls you need to apply configuration states, schedule patch updates, group or migrate systems, and much more.
For those who prefer to work without the web interface, the server command-line tool “spacecmd” offers access to all of the functions of SUSE Manager through a terminal window and supports scripting.
Flexible, Scalable, and Efficient
The flexible and efficient SUSE Manager for Retail adapts easily to your needs. Whether you manage a small shop with five POS terminals or a large chain with a thousand branches, SUSE Manager for Retail will help you configure, administer, and expand your infrastructure as your business grows and changes.
You can manage different departments or companies within the same infrastructure – each with different IT requirements. The main administrator can delegate different tasks to different users; you can subdivide the network and provide separate administrators for each subgroup. Or you can give different admins responsibility for different tasks, such as key activation, images, configuration, and software channels.
SUSE Manager for Retail lets you automate rollout for new branch servers or retail clients using the Salt configuration management system (see the box entitled “About Salt”). The SUSE Manager for Retail web interface lets administrators without advanced scripting skills specify complex system configurations using Salt Formulas and Actions Chains.
SUSE Manager for Retails also lets you manage software updates across the infrastructure in a secure and systematic way.

You can configure a software channel for each device type or use case and automate updates through the channel, ensuring that no device receives software from an unauthorized source.
And SUSE Manager for Retail is not limited to managing devices for retail operations. You can use SUSE Manager for Retail to manage your entire Linux infrastructure, from point-of-sale terminals, to servers, to Linux workstations.
About Salt
SUSE Manager for Retail controls all its branch servers and retail terminals by means of the powerful Salt configuration management system. Salt lets you define a complete configuration for a client system in a descriptive format. A client agent, known as a Salt “minion,” can obtain this information from the Salt master without the need for additional configuration. If the client cannot run an agent, Salt is capable of acting in “agentless” mode, sending Salt-equivalent commands through an SSH connection. The ability to operate in agent or agentless mode is an important benefit for a diverse retail network.
The web interface of SUSE Manager for Retail lets the administrator create Salt Formulas and Action Chains through simple web forms. Salt Formulas are collections of Salt state files that can describe complex system configurations using parameters that make them reusable for similar but not identical systems. Action chains are sequences of Salt instructions that are executable as if they were a single command. Examples of chainable actions include rebooting the system (even in the middle of a series of configuration steps!), installing or updating software packages, and building system images.
Compliance
SUSE Manager for Retail includes tools for managing compliance with internal company policies as well as external regulations. Use SUSE Manager for Retail to create an inventory of all the systems you wish to manage. Once that inventory is available, SUSE Manager for Retail continuously monitors all its clients and reports on any deviation from current patch level or any other compliance requirement.
 SUSE Manager for Retail also supports automatic, system-wide configuration of vulnerability scans, using either CVE (Comm
SUSE Manager for Retail also supports automatic, system-wide configuration of vulnerability scans, using either CVE (Comm
on Vulnerabilities and Exposures) lists or the OpenSCAP framework. You can search for CVE numbers in all patches released by SUSE, or generate custom reports of all the machines affected by a specific CVE. You can view the status of all of your Linux-based POSes and other assets in any moment and quickly identify the ones that need attention. This feature makes it possible to quickly detect “shadow IT” systems installed or reconfigured without central authorization.
New to SUSE Manager Retail 4.1
Improved operational efficiency with new capabilities focused on supporting small store operations, enhanced offline capabilities and image management over Wi-Fi.
1) Most large retailers have diverse store footprints. These may be large stores with hundreds of Point of Service (POS) devices but also smaller branches with only a few. Prior versions of SUSE Manager for Retail required a branch server to be present in each store which increased the cost and complexity of setup for certain environments. With SUSE Manager for Retail 4.1 we introduce the support for small branch operations where the branch server can run remotely in the datacentre or in the cloud. With this you can manage multiple small stores without having to deploy a branch server in each of those stores. From small to very large setups, this reduces complexity of the store infrastructure and lowers cost by reducing unnecessary hardware.
2) When you open new stores, POS devices may be deployed before any network is available at the location. In order to get the new store operational quickly, the POS terminals need to be brought up without the initial network boot cycle. SUSE Manager for Retail 4.1 provides the ability to create an image for the USB as well as for an OEM preload, allowing you to boot the terminal from the USB without having network connectivity upfront at the store.
3) Many stores today only use wireless networking. Adding wired networking in those stores for managing their POS devices would lead to increased costs and complexity. So, being able to manage the deployment and maintenance of POS terminals over the store’s Wi-Fi removes the costs associated with physical networking. Now you have the support for USB boot images, registers can easily be set up and locally booted using Wi-Fi and a USB stick. This provides greater business agility by allowing wireless “holiday registers” to be quickly deployed to meet seasonal demands in store.
Enhanced virtual machine management and monitoring capabilities, enabling fully-integrated store management.
1) A major challenge you may face as a retailer is that store locations are typically geographically distributed with no dedicated IT staff available. In this case server virtualization plays a key role in modernizing a distributed store infrastructure and helps improve operations. With virtualization retail environments can benefit from agility, availability and standardization.
2) In order to stay ahead of the competition and provide the best shopping experience to their customers, retailers need to be able to deploy new applications to the stores quickly and efficiently. The enhanced virtual machine management features of SUSE Manager for Retail 4.1 deliver performance, management and availability improvements to the store operations.
3) SUSE Manager for Retail 4.1 expands the new Prometheus/Grafana-based monitoring stack introduced with version SUSE Manager 4 with enhanced support for large federated and non-routable network environments, ideal for monitoring highly distributed retail environments. Retailers are not only able to monitor their branch servers in the stores but also their store POS devices. This allows the branches to collect metrics from the stores and send to a central aggregator that provides retailers with a centralized view of the health of their stores.
Scale Retail environments without compromise with performance and scalability enhancements.
1) With the increasing prevalence of kiosks, self-checkout devices, IoT devices and digital signage in the stores, your retail environment has probably become very large. With our performance and scalability enhancements, SUSE Manager for Retail can now scale to tens of thousands of end point devices and beyond. This allows you the flexibility to grow your infrastructure as required by your business needs, with the assurance that SUSE Manager for Retail will be able to manage large retail estates.
2) With the “SUSE Manager Hub – Tech Preview” multiserver architecture we’re gradually introducing a framework that allows for scaling retail deployments to the hundreds of thousands of nodes with tiered management servers.
Modernize your Point of Service environment while ensuring reliability and stability with SUSE Linux Enterprise Point-of-Service 15 SP2.
SUSE Manager for Retail 4.1 now provides you will predefined configuration templates to help you build SLES 15 SP2 based POS images. With SUSE Manager for Retail’s automated process, you can easily build and deploy these images on POS hardware in the store. Deploying SLEPOS 15 SP2 images in the POS environment enables retailers to bring new hardware and services into the stores, as well as gain stability for your business critical POS infrastructure with a 7.5 years long-term support for this service pack.
How can SUSE Manager for Retail help me in these unprecedented times?
During these uncertain and unprecedented times IT staff volatility has highlighted that when serious IT staff disruption occurs, home grown tools, disparate management products, remote management issues, lack of automation, and inconsistent monitoring and health checks leave IT seriously compromised. A fully leveraged SUSE Manager solution addresses ALL of the above and much more keeping your servers, VMs, containers and clusters secure, healthy, compliant and low maintenance irrespective of where they are deployed Private, Public or Hybrid cloud.
Conclusion
SUSE Manager for Retail is a fully open source solution, optimized and tailored for controlling the whole lifecycle of retail clients from one interface. Administrators can automatically provision, configure, update, and monitor every Linux client from centrally managed software sources. SUSE Manager for Retail also lets you create pre-configured client configurations and customize them as necessary for flexible and efficient rollout of new systems.
SUSE Manager for Retail will help you improve the uptime, compliance, and quality of service levels for your retail infrastructure, while preventing lock-in and reducing total cost of ownership.
And SUSE Manager for Retail is not limited to point-of-service retail environments: you can also manage your other Linux assets within the same convenient user interface.
To learn more about SUSE Manager
For detailed product specifications and system requirements, please visit: suse.com/products/suse-manager-retail/
For Uyuni details and development, visit www.uyuni-project.org