By Gary Duan
While more and more applications are moving to a microservices and container-based architecture, there are legacy applications that cannot be containerized. Access to these applications need to be secured with egress container security policies when containers are deployed with Kubernetes or Red Hat OpenShift. These legacy applications include database servers and applications developed with .NET frameworks. The cost and risk to migrate these applications to a microservice architecture is so high that many enterprises have a mixed environment where new containerized applications and legacy applications are running in parallel.
Application segmentation is a technique to apply access control policies between different services to reduce their attack surface. It is a well-accepted practice for applications running in virtualized environments. In a mixed environment, containerized applications need access to the legacy servers. DevOps and security teams want to define access policies to limit the exposure of legacy applications to a group of containers. In Kubernetes, this can be achieved by Egress Rules of the Network Policy feature.
This article discusses several implementations of egress policy in Kubernetes and Red Hat OpenShift and introduces the NeuVector approach for overcoming limitations with basic Network Policy configurations.
Egress Container Security with Network Plugins
In Kubernetes 1.8+, an Egress policy can be defined as something like this,
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: app
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 10.10.0.0/16
ports:
- protocol: TCP
port: 5432
This example defines a network policy that allow containers with the label ‘role=app’ to access TCP port 5432 of all servers in subnet 10.10.0.0/16. All other egress connections will be denied.
This achieves what we want to some extent, but not all network plugin support this feature. As of February 2018, according to this link, Calico and Weave Net are the only two network plugins that support this feature commercially.
However, using a subnet address and port to define external services is not ideal. If these services are PostgreSQL database clusters, you really want to be able to specify only those database instances using their DNS names, instead of exposing a range of IP addresses. Using port definitions is also obsolete in a dynamic cloud-native world. A better approach is to use application protocols, such as ‘postgresql,’ so only network connections using the proper PostgreSQL protocols can access these servers.
Egress Container Security with Istio
Istio is an open-source project that creates a service mesh among microservices and layers onto Kubernetes or OpenShift deployments. It does this by “deploying a sidecar proxy throughout your environment”. In the online documents, they give this example for Egress policy.
apiVersion: config.istio.io/v1alpha2
kind: EgressRule
metadata:
name: googleapis
namespace: default
spec:
destination:
service: "*.googleapis.com"
ports:
- port: 443
protocol: https
This rule allows containers in the ‘default’ namespace to access subdomains of googleapis.com with https protocol on port 443.
The article cites two limitations,
- Because HTTPS connections are encrypted, the application has to be modified to use HTTP protocol so that Istio can scan the payload.
- This is “not a security feature“, because the Host header can be faked.
To understand these limitations, we should first examine how a HTTP request looks like.
GET /examples/apis.html HTTP/1.1
Host: www.googleapis.com
User-Agent: curl/7.35.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
In the above example, you can see that when you type,
curl http://www.googleapis.com/examples/apis.html
in the first portion of the URL, ‘www.googleapis.com‘, does not appear in the first line of the HTTP request, which only contains the path. It shows up as the Host header. This header is where Istio looks for to match the domain defined in its network policy. If HTTPS is used, everything here is transmitted encrypted so Istio cannot find it. A compromised container can replace the header and trick Istio to allow traffic to a malicious IP.
In fact, the third limitation that the documentation doesn’t mention is that this approach only works with HTTP. We cannot define a policy to limit access to our PostgreSQL database cluster.
DNS-based Egress Container Security with NeuVector
Once the NeuVector Enforcer container is deployed on a container host, it automatically starts monitoring the container network connections on that host with DPI technology (deep packet inspection). DPI enables NeuVector to discover attacks in the network. It can also be used to identify applications and enforce a network policy at the application level when deployed as a complete Kubernetes security solution.
Once a network policy with the whitelisted DNS name(s) is pushed to the Enforcer, the Enforcer’s data path process starts to silently inspect the DNS requests issued by the containers. The Enforcer does not actively send any DNS request, so no additional network overhead is introduced by NeuVector. It parses DNS requests and responses, and correlates the resolved IP with the network connections made by the specified containers. Based on the policy defined, the Enforcer can allow, alert or deny the network connections.
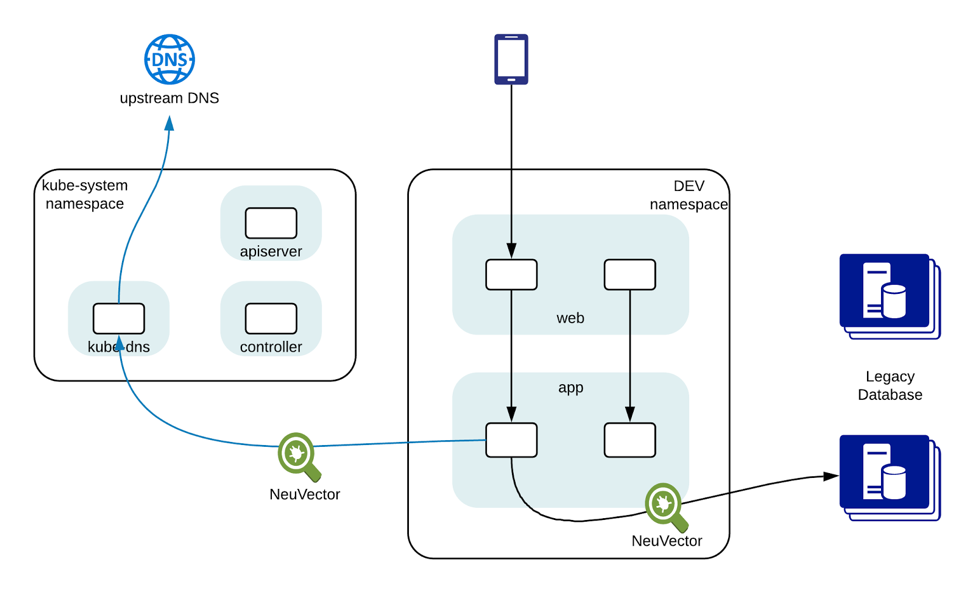
This approach works on both unencrypted and encrypted connections, and it will not be tricked by any faked headers. It can be used to enforce policies on any protocol, not just HTTP or HTTPS. More importantly, because of the DPI technology, the Enforcer can inspect the connections and make sure only the proper PostgreSQL protocol is used to access the PostgreSQL databases.
Kubernetes and OpenShift run-time container security should include control of ingress and egress connections to legacy and API-based services. While there are basic protections built into Kubernetes, Openshift, and Istio, business critical applications need enhanced security provided by Layer 7 DPI filtering to enforce egress policies based on application protocols and DNS names.
About the Author: Gary Duan
Gary is the Co-Founder and CTO of NeuVector. He has over 15 years of experience in networking, security, cloud, and data center software. He was the architect of Fortinet’s award winning DPI product and has managed development teams at Fortinet, Cisco and Altigen. His technology expertise includes IDS/IPS, OpenStack, NSX and orchestration systems. He holds several patents in security and data center technology.



 SUSE Expert Days
SUSE Expert Days As critical as it is to protect application containers deployed by Kubernetes, it is just as critical to protect the Kubernetes system containers from attacks or from being used in an attack. In this post I’ll focus on one important Kubernetes security area – protecting the Kubelet, which manages the pods on a worker node. The recent Kubernetes exploit at Tesla where crypto mining software was installed on servers by exploiting a open Kubernetes console makes it critical to examine potential attack surfaces for all Kubernetes system containers.
As critical as it is to protect application containers deployed by Kubernetes, it is just as critical to protect the Kubernetes system containers from attacks or from being used in an attack. In this post I’ll focus on one important Kubernetes security area – protecting the Kubelet, which manages the pods on a worker node. The recent Kubernetes exploit at Tesla where crypto mining software was installed on servers by exploiting a open Kubernetes console makes it critical to examine potential attack surfaces for all Kubernetes system containers.


 PARTY with SUSE at IBM Think
PARTY with SUSE at IBM Think
