By Gary Duan
The Equifax data breach is one of the largest and costliest customer data leaks in history. Let’s take a closer look at the vulnerabilities and exploits reportedly used. Could the use of containers have helped protect Equifax? We’ll examine how proper security in a container based infrastructure helps to make application security more effective.
The Apache Struts Exploit
Apache Struts is a widely used framework for creating web applications in Java. It was initially believed that the newly-published Struts vulnerability, CVE-2017-9805, was responsible for the Equifax data breach. However, the latest announcement from Equifax indicates that it was vulnerability CVE-2017-5638, which was discovered in March, that allowed the Equifax data breach. Before talking about what security strategies can prevent this type of incident, it’s useful to understand the nature of both vulnerabilities.
The vulnerable code of CVE-2017-9805 resides in the REST plugin of the Struts framework. The plugin fails to validate and deserialize safely the user uploaded data in the HTTP request. This allows attackers to write arbitrary binary code to the web server and execute it remotely.
Once this vulnerability was reported, within days, working exploits had appeared publicly. Here is a snippet of one proof of concept.

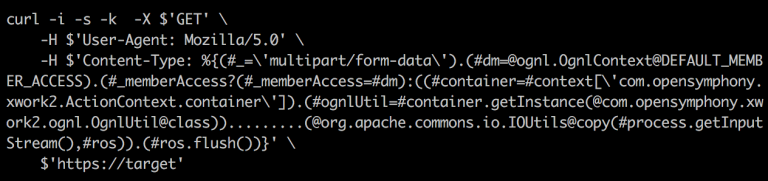
Earlier this year, in March, the vulnerability CVE-2017-5638 was reported in the Jakarta multi-part parser. By injecting a crafted Content-Type HTTP header with a ‘#cmd=’ string, the attacker is also able to execute arbitrary commands on the web server. An attack sample is shown below (for security reasons, only a partial attack vector is shown).
Container Security vs. VM and Physical Server Security
Using an application container provides some extra layers of protections compared to VMs and physical servers. Containers take a very declarative way to build an application image, using a Dockerfile. Container images can be easily scanned before deployment to find known vulnerabilities. If deployed correctly using a microservice architecture, once a patched, updated software version is available for any vulnerability, the vulnerable application(s) can be easily swapped out.
However, containers themselves provide benefits mainly for modern DevOps teams and workflows. Containers don’t provide enhanced security protections at runtime. Consider the attack window before a vulnerability is published, before a patched software version is available, and before an enterprise is able to install or implement the corrective action. In the Equifax data breach this took at least two months, maybe more. Simply switching to containerized applications won’t stop attackers from advancing forward in the exploit ‘kill chain’ and stealing the assets which are valuable to consumers, enterprises, and hackers.
Lateral Movement and Application Segmentation
Once attackers gains access to a web server, they can effectively bypass all security measures at the edge. Attackers can enter the inner communication cycle where the applications are running, whether it’s in a public cloud or private data center. Often, internal networks, where east-west traffic is less monitored, are an open space for attackers to explore. Remember in a similar recent exploit, attackers could use the Dirty Cow linux exploit to gain root access to a server if they could execute arbitrary code remotely.
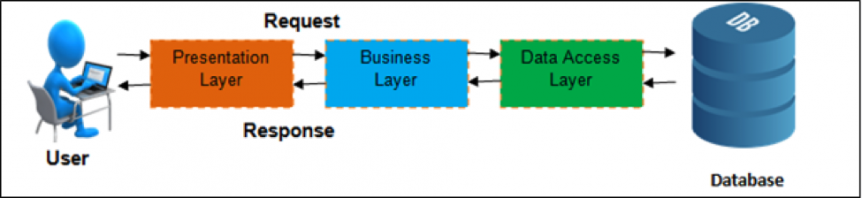
However, after a successful Dirty Cow or Apache Struts vulnerability is successfully exploited, what gets compromised is still just one web server. The diagram above depicts a typical multi-tier architecture. After getting a foothold at the presentation or the business layer attackers have to make lateral moves within the data in order to reach sensitive data stored in the database.
A common lateral move involves scanning internal networks to attempt to make connections to the database. Attackers may also download tools from the Internet to launch further exploits. These activities in the ‘kill chain’ give us an opportunity to identify suspicious activity and prevent malicious code from being spread to other parts of the data center.
 For example, a ‘container firewall’ provides application segmentation techniques to create a whitelist of allowed container connections. This policy can enforce that internal applications such as web servers cannot initiate connections to external networks, or to access the database. The whitelist establishes that the web server has to go through the data access layer, and direct connections are strictly prohibited. When these policies are in place and enforced, it will become significantly difficult for the attackers to explore internal networks because any attempt to do so will be immediately detected. With the limited application function, scope and network behavior defined for container microservices it becomes easier to detect suspicious activity.
For example, a ‘container firewall’ provides application segmentation techniques to create a whitelist of allowed container connections. This policy can enforce that internal applications such as web servers cannot initiate connections to external networks, or to access the database. The whitelist establishes that the web server has to go through the data access layer, and direct connections are strictly prohibited. When these policies are in place and enforced, it will become significantly difficult for the attackers to explore internal networks because any attempt to do so will be immediately detected. With the limited application function, scope and network behavior defined for container microservices it becomes easier to detect suspicious activity.
Deep Packet Inspection (DPI)
According to the Equifax investigation, the initial attacks took place between May and July, at least two months after CVE-2017-5638 had been published in March. Had a set of DPI-enabled pattern match signatures been deployed, the compromise could have been prevented. The attack vectors within all the working exploits use predictable patterns. The malicious HTTP requests either have a malformed header or have an executable shell command embedded in the XML object. However, these indicators are only obvious to people or detection tools that understand how the protocols and applications work. Signatures can be developed based on the attack patterns, but to limit the false positive and false negative alerts, we must resort to DPI (deep packet inspection) techniques.
The text patterns in these attacks, although appearing to be very abnormal, can be present in absolutely legitimate traffic. A DPI capability is able to:
- Parse the entire HTTP request
- Mark HTTP protocol units, such as URI, Header and body
- Normalize the request content and remove evasion attempts
- Recognize the file and object format in transmission and reconstruct content.
All of this context helps the pattern match algorithms to accurately look for patterns within specific locations. DPI is a critical capability to determine, in real-time, on a connection by connection basis, whether the packets should be allowed through, blocked, or generate an alert.
With the use of containers and application segmentation, the attack surface of modern applications is greatly reduced. And if DPI is used for container traffic it becomes more difficult for hackers to go undetected for so long like in the Equifax data breach.
About the Author: Gary Duan
Gary is the Co-Founder and CTO of NeuVector. He has over 15 years of experience in networking, security, cloud, and data center software. He was the architect of Fortinet’s award winning DPI product and has managed development teams at Fortinet, Cisco and Altigen. His technology expertise includes IDS/IPS, OpenStack, NSX and orchestration systems. He holds several patents in security and data center technology.

 In today’s business environment, organizations worldwide are striving to become digital businesses.
In today’s business environment, organizations worldwide are striving to become digital businesses. 






 Since this is our initial set up, we need to add a host to our Rancher environment:
Since this is our initial set up, we need to add a host to our Rancher environment: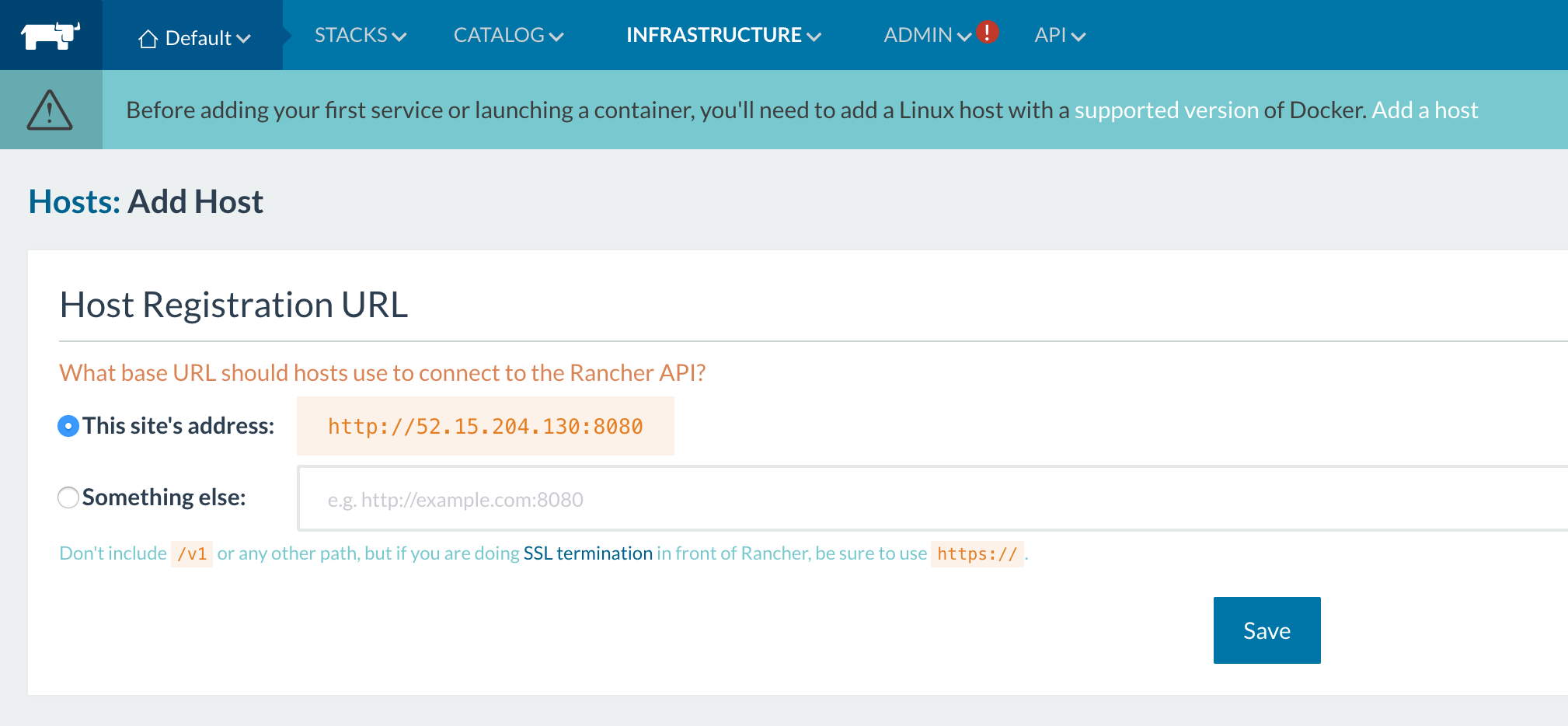
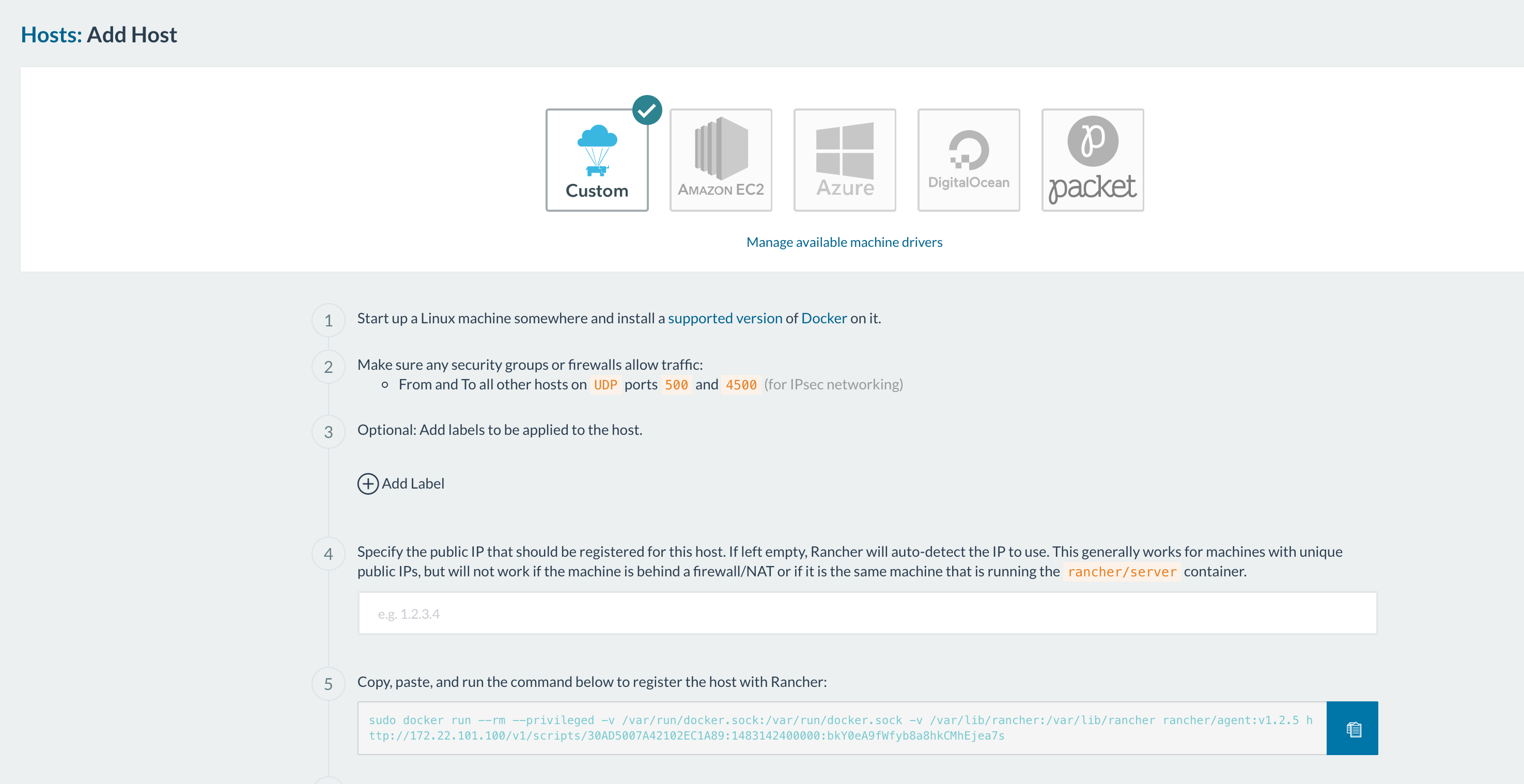 (note: the ports that have to been open for hosts to be able to communicate are 500 and
(note: the ports that have to been open for hosts to be able to communicate are 500 and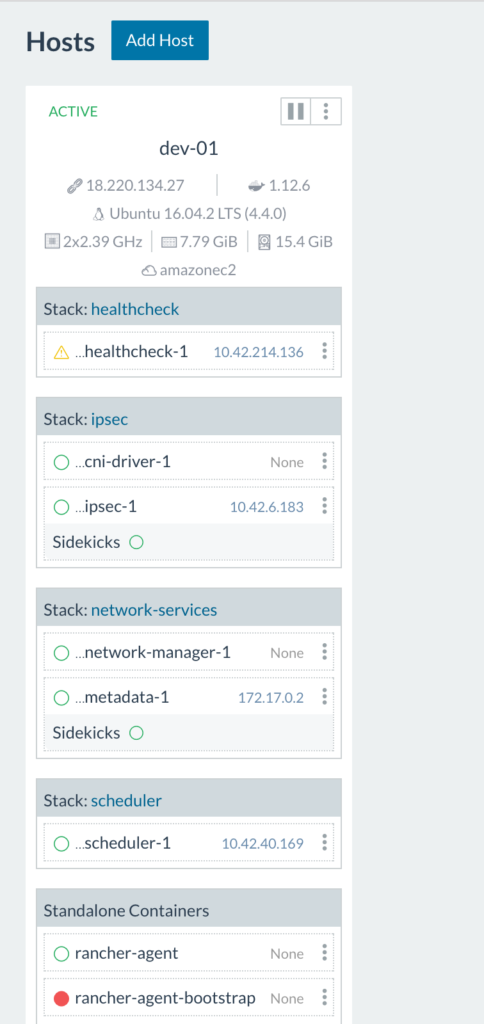
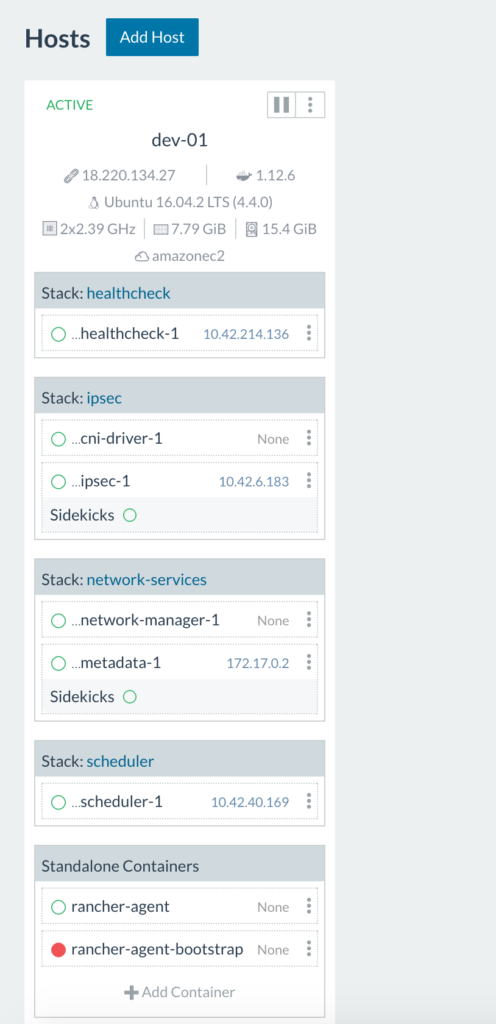





 It’s Rancher being unable to reach the database server or authenticate with the credentials we’ve provided it in our start up command. Take a look at networking settings, username and password and access privileges in the MySQL
It’s Rancher being unable to reach the database server or authenticate with the credentials we’ve provided it in our start up command. Take a look at networking settings, username and password and access privileges in the MySQL


