Developers often believe that demonstrating the need for an IT-based solution should be very easy. They should be able to point to the business problem that needs a solution, briefly explain what technology should be selected, and the funds, staff, and computer resources will be provided by the organization. Unfortunately, this is seldom the actual process that is followed.
Developing a Business Case for New Technology Isn’t Always Easy
Most organizations require that both a business and a technical case be made before a project can be approved. Depending on the size and culture of the organization, building both cases can be a long, and sometimes arduous, process.
Part of the challenge developers face can be summed up simply: business decision-makers and technical decision-makers have different priorities, use different metrics, and, in short, think differently.
Business Managers Think in Different Terms Than Developers
Business decision-makers are almost always thinking in terms of the investment required, the costs expected, and the revenues the organization can expect that can be attributed to the successful completion of the project not the technical merit, the tools selected, or the development methodology that will be deployed to complete the project.
They may use technology every day, but many think of it as a means to an end, not something they enjoy using.
As David Ingram pointed out in his recent article on business decision making, managers often use a 7-step process:
- Identify the problem
- Seek information to clarify what’s actually happening
- Brainstorm potential solutions
- Weigh the alternatives
- Choose an alternative
- Implement the chosen plan
- Evaluate the outcome
You’ll note that the best technology, the best approach to development, the best platform, how to achieve the best performance, how to achieve the highest levels of availability, and other technical factors that technologists consider may be seen as secondary issues. From the perspective of a business decision-maker, the extensive work that constitutes this type of evaluation might all be wrapped up into the “weigh the alternatives” step.
Factors of the Business Decision
Let’s break this down a bit. Business decision-makers will consider the *overall** investment required and weigh it against the potential benefits that might be received. This includes a number of factors that may not appear to be directly associated with a specific project.
They also will be considering if this the right project to be addressing at this time or whether other issues are more pressing.
While working with an executive at a major IT supplier, I was once told “solving the wrong problem, no matter how efficiently and well-done, is still solving the wrong problem.”
Here are a few of the factors they are likely to consider:
- Staff: the number of staff, the levels of expertise, the amount of time they’ll need to be assigned to the project, the business overhead associated with having those people on staff, whether they should be full-time, part-time, or contractors
- Costs: the costs of all resources required, including:
- Data center operational costs: floor space, power, air conditioning, networking, maintenance, real estate
- Systems: number of systems, memory required, external storage, maintenance
- Software: software licenses, software maintenance
- Time to market: can this project be completed quickly enough to address the needs of the market. This sometimes is called “time to profit.”
- Revenues: will the project directly or indirectly lead to increased revenues?
If the costs of doing the project outweigh the projected revenues that can be attributed to the completion of the project, the business decision-makers are likely to look for another solution which may include not doing it at all, purchasing a packaged software product that will solve the problem in a general way, or subscribing to an online service that will address the issue.
In the end, business decision-makers will be focused on increasing the organization’s revenues and decreasing its costs.
What Developers Think About
Developers, on the other hand, tend to think more about the technical problem in front of them and how it can be solved.
What Needs to Be Accomplished
Often, a developer’s first consideration is to fully understand what needs to be accomplished to address the situation. It is quite possible that the developers will be unable to focus on the issues in a way that takes into account the needs of the whole organization. This siloed perspective sometimes results in several business units solving the same problem in different, and sometimes incompatible, ways.
How It Can Be Accomplished
The next consideration for developers is how a solution can be accomplished. Developers are very busy people and need to get things done quickly and efficiently. This often means that they select development tools and methodology they are most familiar with rather than casting about to discover new, and potentially better, approaches. The result is that, from an outsider’s perspective, developers will select the same tool regardless of if it is the best one for the job. As Abraham Maslow pointed out, “I suppose it is tempting, if the only tool you have is a hammer, to treat everything as if it were a nail” (“The Psychology of Science” 1962).
How To Systematize or Automate Solutions
Developers have a tendency to also focus on how to systematize or automate the approach to accomplishing a solution. Developers who have experience introducing new systems will not only consider how to accomplish this difficult task, but also whether the current manual processes have some merit as well.
Costs Are Often Ignored or Secondary to Other Considerations
Developers often do not have access to reports showing the overall costs, the investment required, or even the revenues of a given project. Since they are busy working on projects, they often don’t think about those factors at all. This situation, by the way, is the root of many communication challenges faced when developers are attempting to persuade business decision-makers to approve a project. They don’t have all of the data they need.
I’m reminded of a conversation with a CFO of my company who didn’t understand the need for a different type of database than the one used by the company for another purpose. At first I thought of him a “a man who knows the price of everything and the value of nothing,” to quote Oscar Wilde.
After thinking about his comments, I built a different justification that focused on speaking to him in his own language by discussing the project in terms of the investment required, the costs that were going to be incurred, and the revenue potential the new approach would provide. It took some work to obtain that information, but it was worth the effort in the end.
It was only after a longer conversation with the CFO that he began to be able to understand why Lotus Notes wasn’t the best tool for the creation of a transaction-oriented system for research and analysis.
Are you speaking to your business decision-makers using acronyms, development procedures and the names of open source projects you’d like to deploy? If so, you’re not helping your cause.
Where to Start
A good place to start is to think in terms of where and how money can be saved, where and how previous investments can be enhanced or reused rather than being discarded, and how your proposed project would result in increased opportunities for revenue.
It would also be wise to offer a vision of how the use of containers will help the organization achieve its overall goals, including factors such as:
- Scaling to address the needs of a larger or at least a new market
- Reducing overall IT costs
- Allow the organization to rapidly adapt to a rapidly changing environment, to take advantage of emerging opportunities
- Quickly develop new products or services
- Reach new customers while being able to maintain relationships with today’s customer base
For Many Companies Adoption of Containers Must Be Carefully Justified
The move to a Container-based environment is one of those journeys that developers can easily understand as beneficial that can be challenging to justify to a business decision-maker.
After all, some things aren’t fully known until they’ve been done at least once. So, quantifying investments required, cost savings that will be realized, and the actual size of revenue increases can be difficult.
What can be said is that adopting Containers can reduce costs and reduce risk by supporting rapid and inexpensive prototyping of solutions. Pointing out that doing this prototyping in inexpensive cloud computing services rather than acquiring new systems would help them understand that you are focused on meeting your objects while still helping the organization keep costs under control. Tell the business decision makers that this approach also offers them a choice in the future. Once something is developed, documented, and proven to be able to do the job, it can either stay where it is or be moved in-house depending upon which will be the best overall business decision.
Where Can Containers Help a Company Reduce Costs?
Developers understand that being able to decompose a problem into smaller, more manageable problems can improve their efficiency, reduce their time-to-solution, and make reuse of code and services easier.
Reducing the Number of Operating System Instances to Maintain
Explain that containerized applications need fewer copies of operating systems when compared to using virtual machine technology, less processor power, less system memory, and less external storage. Developers can to speak in terms of reducing system requirements and how they can result in a direct savings that the business decision-makers can appreciate.
A few related factors are helpful to bring up as well. This approach reduces the number of software licenses that are required and the cost of software maintenance agreements.
Increasing the Amount of Useful Work Systems Can Accomplish
Since the systems won’t be carrying the heavy weight of unneeded operating systems for each application component or service, performance should be improved. After all, switching from one container to another is much faster than switching from one VM to another. There is no need to roll huge images into and out of storage.
Improving Productivity
Since productivity is important to most organizations, show that a move to containers is a great foundation for the use of a rapid application development and deployment (DevOps) strategy. By decomposing applications into functions, application development can be faster because functions are easier to build, document, and support. This should result in lower development costs while improving overall time to solution.
This approach also can reduce the time to deployment because functions can be developed in parallel by smaller independent teams.
Improving Application Capabilities
Adopting a container-based approach provides a number of other benefits that should be mentioned as well, including:
- Container management and automation functions are improving all the time which should result in lower costs of administration and operations
- Container workload management and migration technology is also improving all the time which should result in higher levels of application availability, higher levels of performance, and fewer losses due to downtime
- Decomposing applications into independent functions and services also makes them easier to develop and maintain which should reduce the costs of development, support, and operations
Facilitating a Move to the Cloud
Most business decision-makers have read about cloud computing, but don’t really understand how it can be adopted. Help them understand that the adoption of containers can facilitate the organization’s ability to deploy functions or complete applications locally, in the cloud, or in a combined hybrid environment, quickly and easily.
So, the answer to the question of whether to move to the cloud or continue on-premise computing is “yes, both.”
Reducing Time to Profit
When the business decision-maker begins to understand the business benefits of containerization, they’ll also see that this approach not only can reduce the overall time to market for applications, but, more importantly, it can reduce the time to profit. Lower development and support costs combined with rapid development can lead to quicker streams of revenue and profit.
Establishing a Foundation for the Future
It is also helpful for the business decision-maker to understand that one of your goals is establishing a platform for the future. Containers are supported in many different computing environments, by many different suppliers, and the organization gets the benefits.
Some of those benefits are:
- Containerized functions can be used as part of many applications without having to be rearchitected or redeveloped
- They can be enhanced or updated as needed without requiring other unrelated functions to be changed.
- Support of the application can be easier and less costly.
- Scalability is improved since the same functions can be run in multiple places with the help of workload management technology
How Can Containers Help a Company Increase Revenue?
A key question to consider is how adopting Containers can help the company increase its revenues. There are a number of elements that directly and indirectly address that question.
Since applications can be developed quicker, perform better, and can be supported more easily, the organization can address a rapidly changing business and regulatory environment more effectively. This also means that the organization can capture additional market share from organizations that continue to only use older approaches to information systems.
It also means that the organization can conduct experiments and prototype solutions quickly. This means that the organization can succeed or fail quicker and that organizational learning will be accelerated.
Where an application or its components execute are flexible. This means that a successful solution can execute locally, in the cloud, or in both places as needed. Business decision-makers usually appreciate flexible solutions that don’t impose extra costs.
This approach also ensures that the resulting solutions can scale from small to large as needed. So, organizations can feel more comfortable trying out something new and know that if it succeeds, it can be put into production effectively. Business decision-makers are often encouraged by approaches that allow for a low investment at first and with opportunities for growth as revenues increase rather than forcing a heavy investment up front. This means that the organization is exposed to lever levels of risk.
Summary
Adopting a container-focused approach can be beneficial to both technical and business decision-makers because it addresses the needs for rapid and effective solution development and reduction in overall costs and risks. It also results in a foundation for future growth and the ability to address a changing market.
This approach brings greater complexity along with it, but the benefits outweigh the challenges in many environments. The rapid improvement in container system management, automation, as well as the strong industry support for this approach makes it a safer choice.
If developers focus on helping business decision-makers understand how this approach also facilitates lower costs, improved time to market, and time to profit, the business side is likely to get on board quicker. They are likely to appreciate the reduced costs of solution support, operations, and development. They are also likely to be pleased that future investment can be based on revenue production rather than facing investing up front based upon a rosy forecast for future revenues.
Developing a Strategy for Kubernetes adoption
Like containers, Kubernetes sits at the intersection of DevOps and ITOps and many organizations are trying to figure out key questions such as: who should own kubernetes, how many clusters to deploy, how to deliver it as a service, how to build a security policy, and how much standardization is critical for adoption. Rancher co-founder Shannon Williams discusses these questions and more in the free online class Building an Enterprise Kubernetes Strategy.
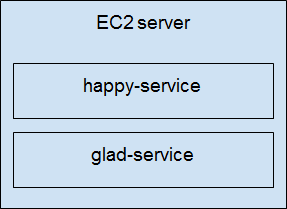 This simple
This simple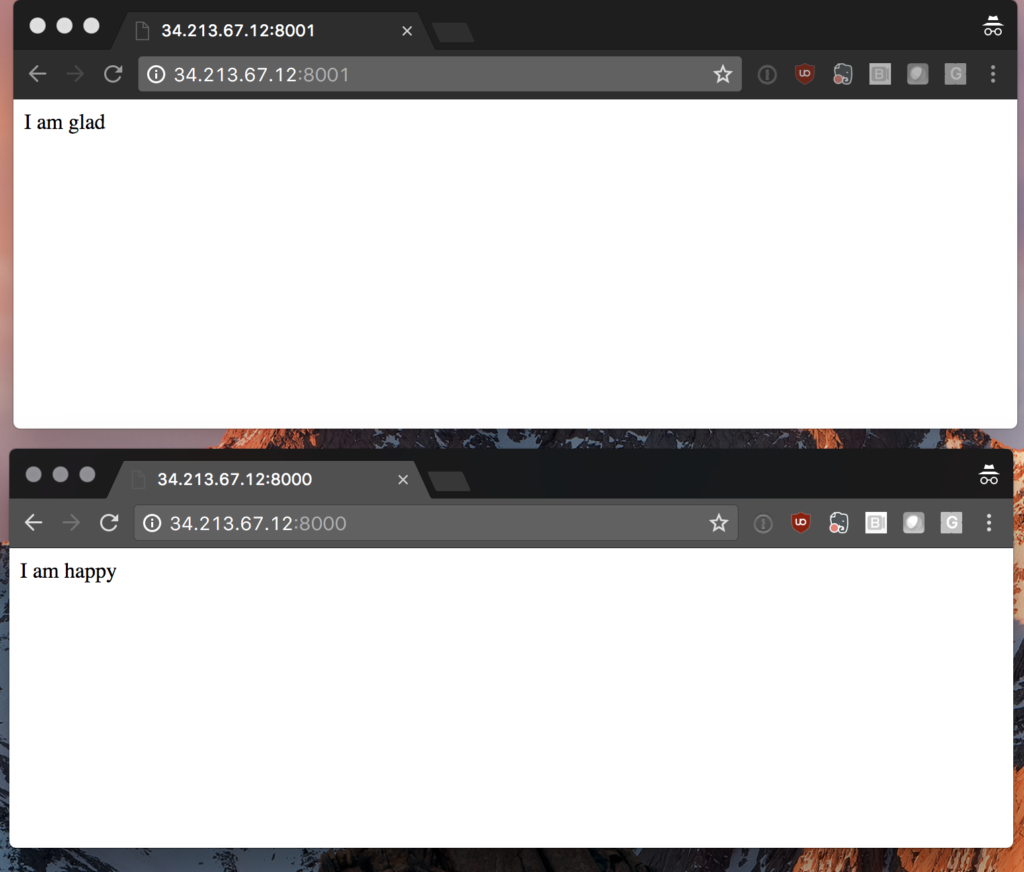 We’ve created each
We’ve created each
 A business guide to effective
A business guide to effective Written with a
Written with a
