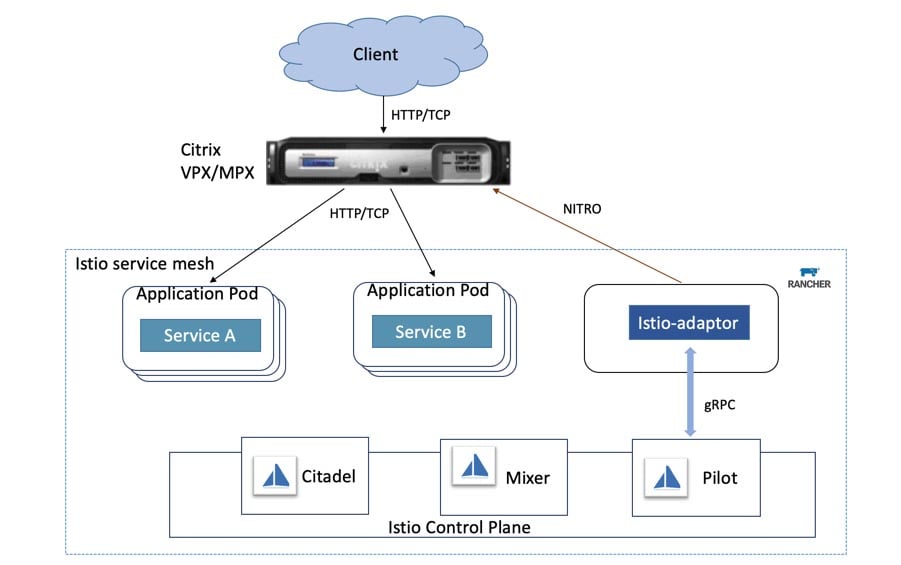
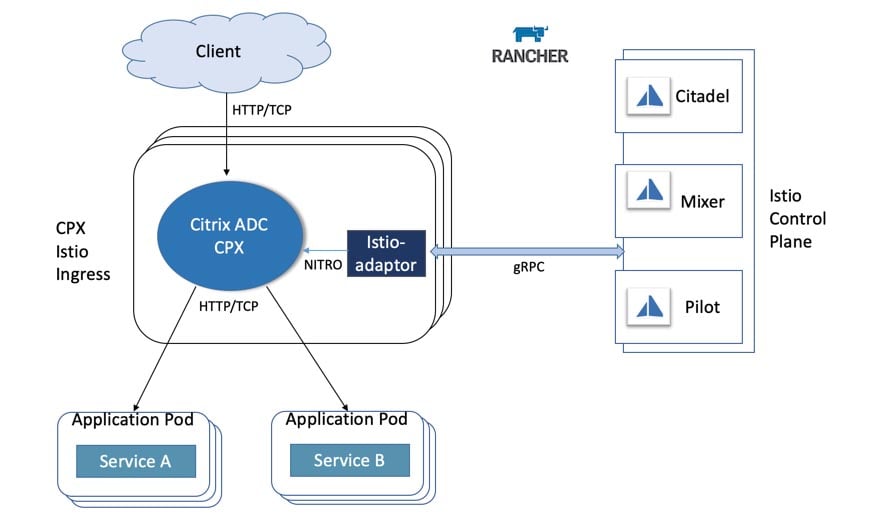
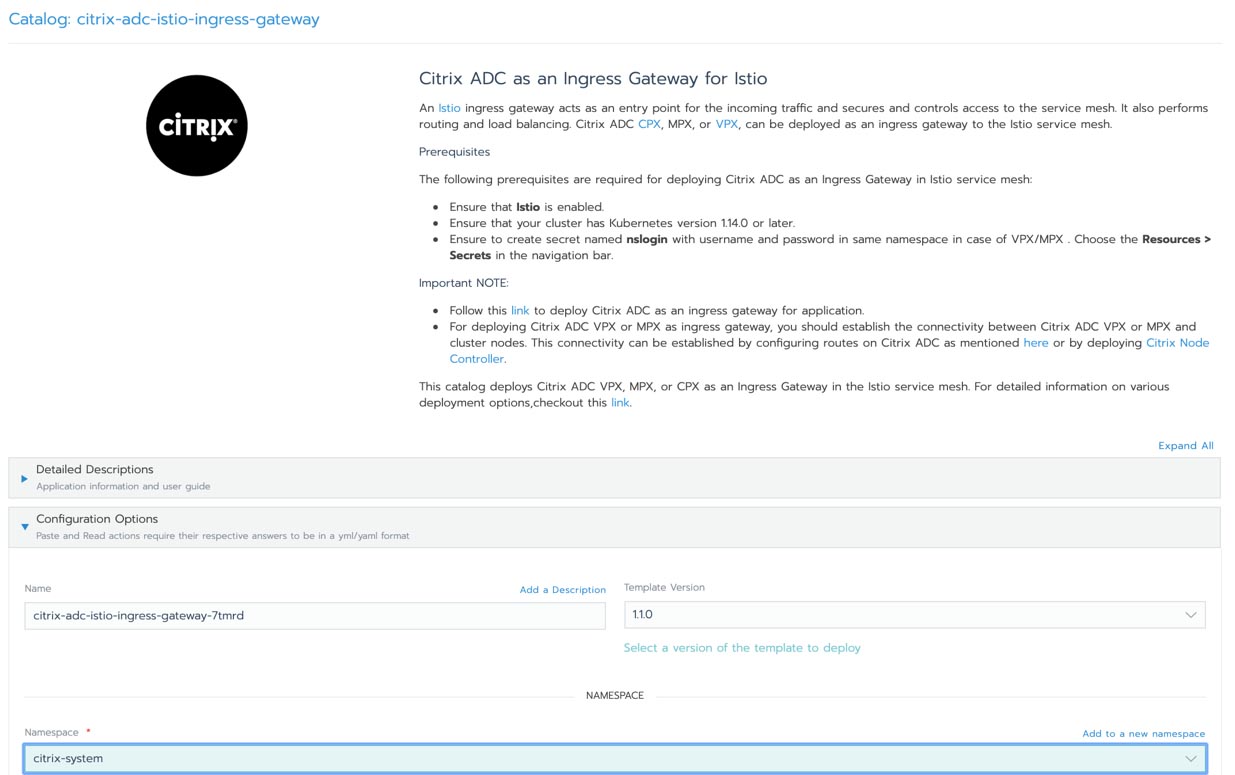
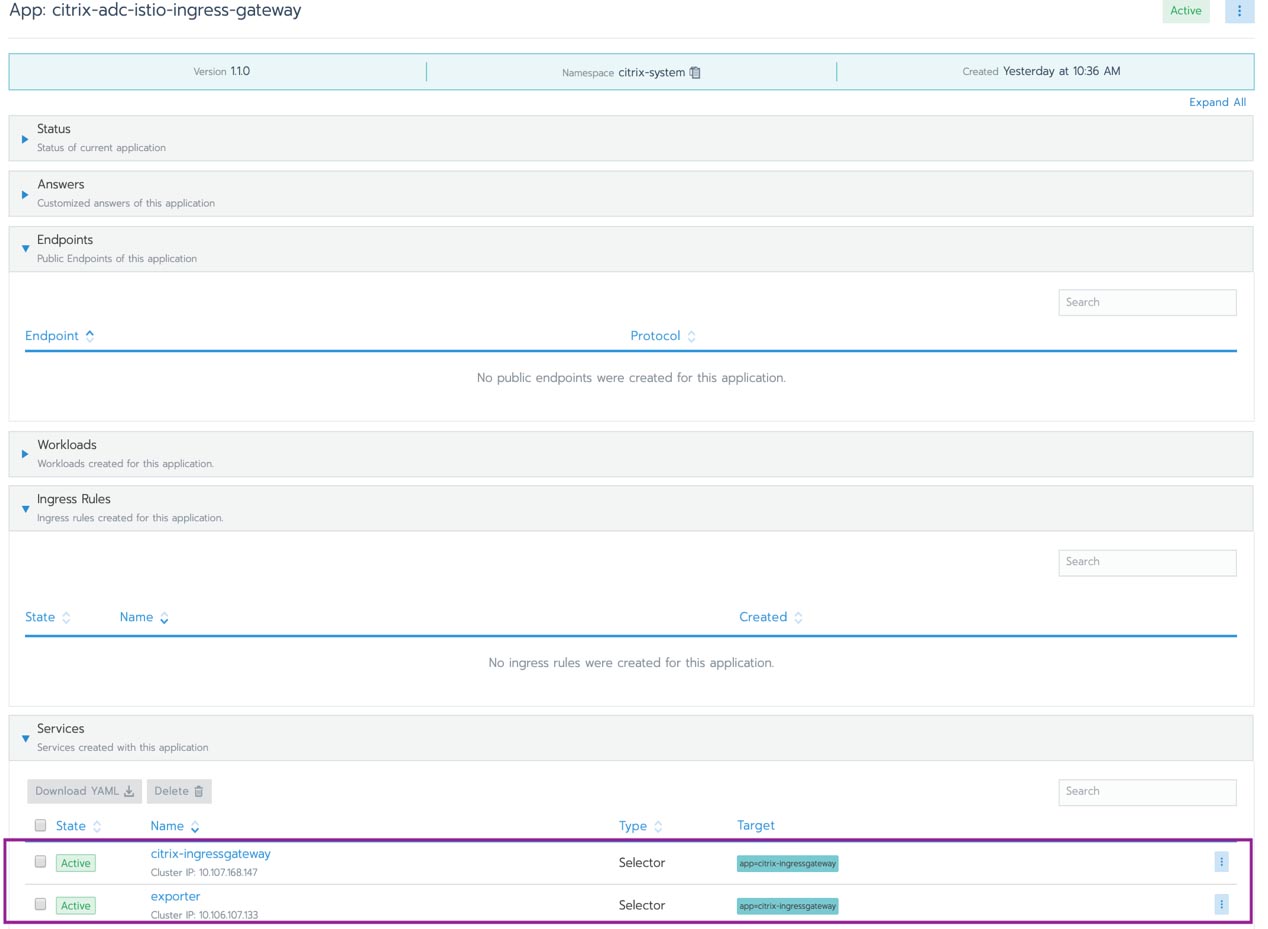
SUSE and Rancher – Enabling our Customers to Innovate Everywhere
In July, I announced SUSE’s intent to acquire Rancher Labs, and now that the acquisition is final, today we embark on a new journey with SUSE. I couldn’t be more excited about our future and what this means for our customers around the world.
Just as Rancher made computing everywhere a possibility for our customers, with SUSE, we will empower our customers to innovate everywhere. Together we will offer our customers possibilities that know no limitations from the data center to the cloud, to the edge and beyond. This is our purpose; this is our mission.
Only our combined company can make this a reality by combining SUSE’s market leadership in powering mission-critical business applications and systems with Rancher’s market-leading Kubernetes management platform. Our independent approach puts the “open” back into open source software, giving our customers the agility to tackle their innovation challenges today and the freedom to evolve their strategy and solutions for tomorrow.
Since we announced the acquisition, I have been humbled by the countless emails and calls that I have received from our customers, partners, members of the open source community and, of course, our Rancher team members. They remain just as passionate about Rancher and are even more excited about our future with SUSE. Our customers worldwide can expect the same innovation that they have come to love from Rancher, now paired with SUSE’s stability and rock-solid IT infrastructure. This will further strengthen the bond of trust that we have created with our customers.
Here’s how we will bring this vision to life:
Customers
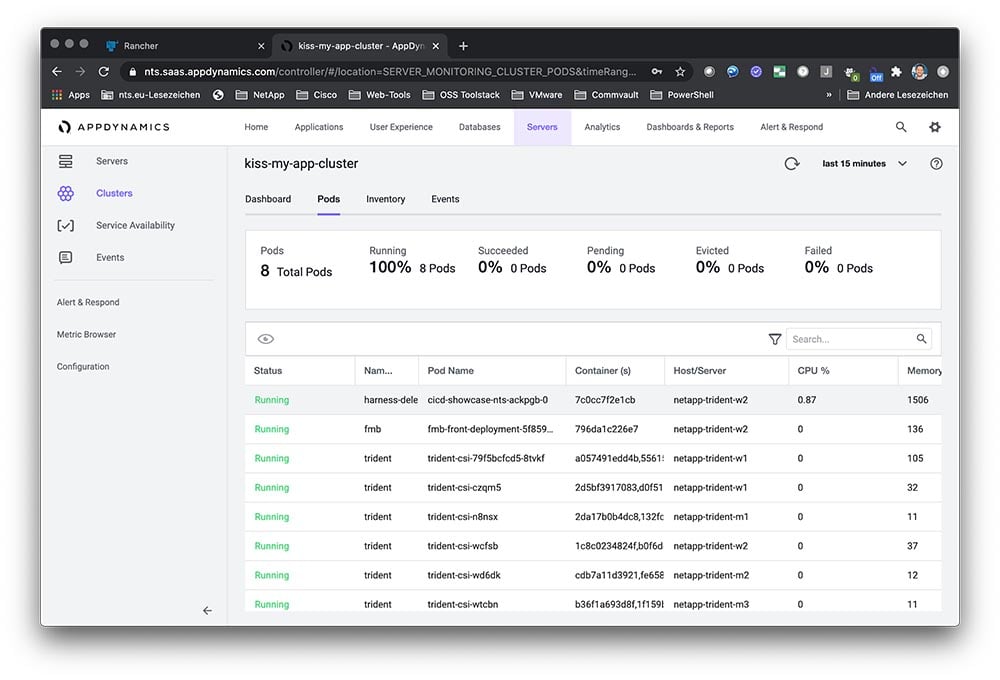
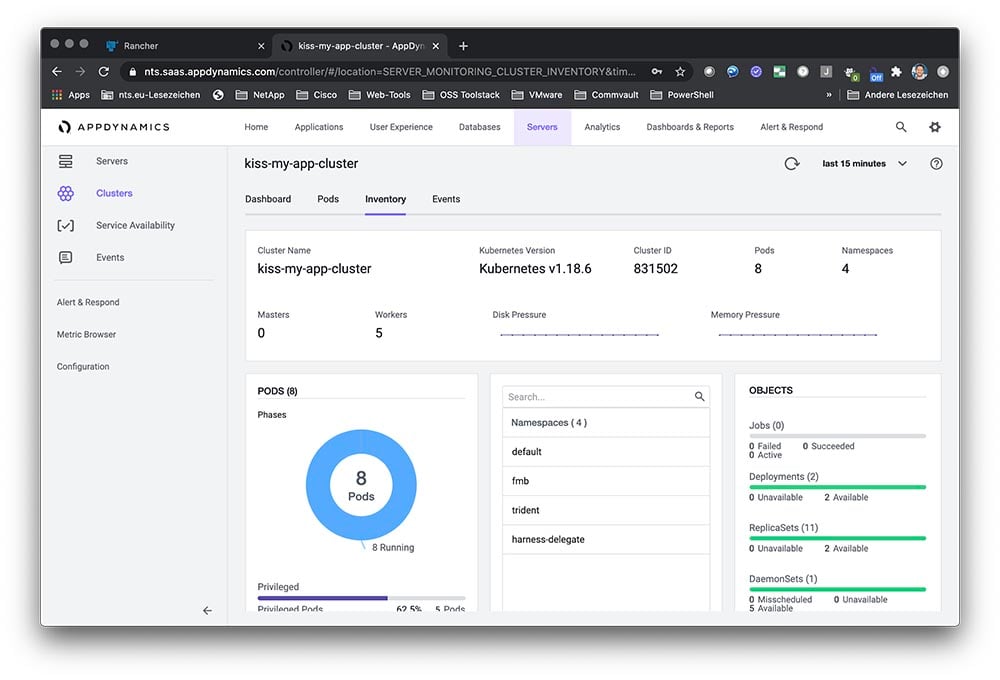
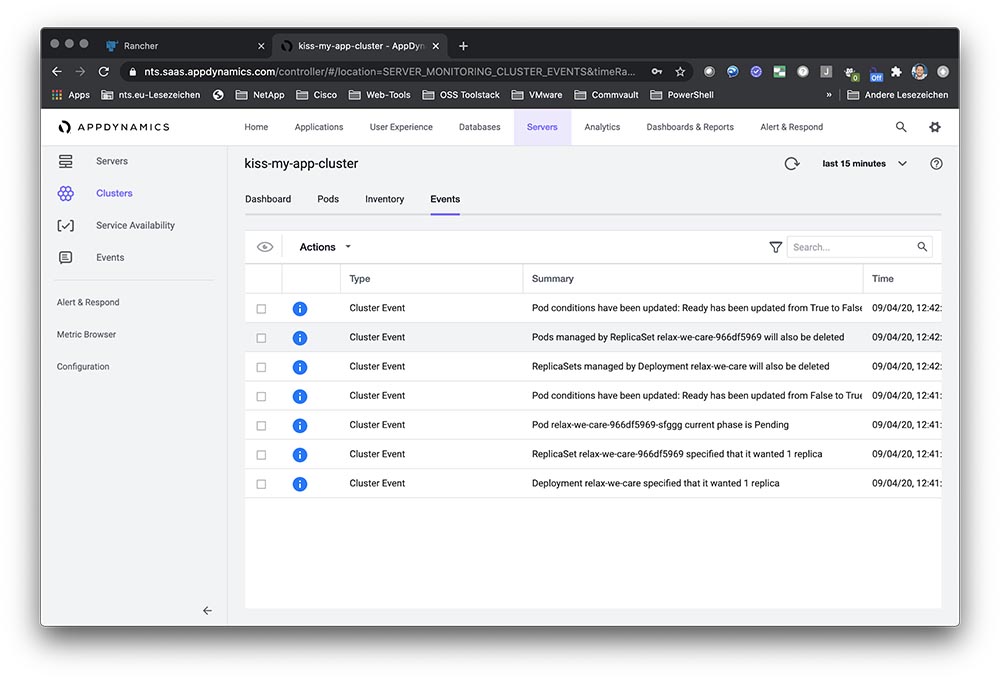
SUSE and Rancher customers can expect their existing investments and product subscriptions to remain in full force and effect according to their terms. Additionally, the delivery of future versions of SUSE’s CaaS Platform will be based on the innovative capabilities provided by Rancher. We will work with CaaS customers to ensure a smooth migration. Going forward, we will double down on our strengths in the areas of security, compliance, governance and broad application certification. A combined SUSE and Rancher provides the only enterprise Kubernetes platform that manages all of the world’s Kubernetes distros, regardless of what underlying Linux distro they use and whether they run in public clouds, private data centers or edge computing environments.
Partners
SUSE One partners will benefit from SUSE’s increased portfolio with Rancher solutions as they will help you close opportunities where your customers want to reimagine the way they manage and scale workloads consistently, monitor the health of their clusters and simplify the deployment and management of container applications.
I invite all Rancher partners to join SUSE’s One Partner Program. You can learn more during this webinar.
Open Source Community
I mentioned it earlier, but SUSE and Rancher remain fully committed to the open source community. We will continue contributing to upstream open source projects. This will not change. Together, as one company, we will continue providing true 100 percent open source solutions to global customers.
Don’t just take my word for it. See what our customers and partners are saying in Forbes.
Our future with SUSE is so bright – this is just the start of an incredible journey.
Join us on December 16 for Innovate Everywhere: How Kubernetes is Reshaping Enterprises. This webinar features Shannon Williams, Co-Founder, President and Chief Revenue Officer, Rancher Labs and Arun Chandrasekaran, Distinguished VP Analyst, Gartner.